
Cum să alegi site-ul web Scraper potrivit pentru nevoile tale
Publicat: 2024-02-06În lumea actuală bazată pe date, capacitatea de a culege eficient informații de pe web poate oferi companiilor un avantaj competitiv semnificativ. Cu toate acestea, cu o multitudine de instrumente de scraping web disponibile, selectarea celui potrivit pentru nevoile dvs. specifice poate fi o sarcină descurajantă. La PromptCloud, înțelegem importanța de a face o alegere în cunoștință de cauză, așa că am compilat acest ghid cuprinzător pentru a vă ajuta să alegeți site-ul web scraper perfect.
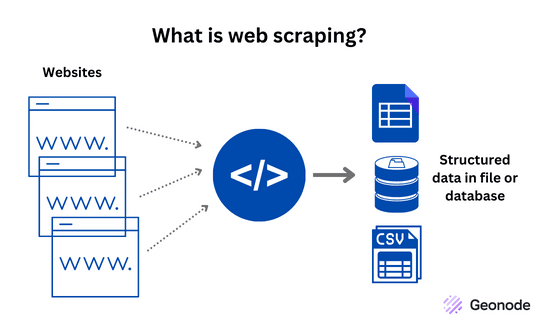
Sursa: https://geonode.com/blog/what-is-web-scraping
Înțelegerea nevoilor dvs. de răzuire
Înainte de a vă scufunda în marea sculelor de răzuit, este esențial să aveți o înțelegere clară a cerințelor dumneavoastră. Luați în considerare următorii factori:
- Volumul datelor : estimați cantitatea de date pe care trebuie să o răzuiți. Diferite instrumente sunt optimizate pentru diferite scări de extragere a datelor.
- Complexitatea site-urilor web : Unele site-uri web sunt mai complexe decât altele, folosind tehnologii precum AJAX și JavaScript, care pot complica extragerea datelor.
- Format de date : determinați în ce format aveți nevoie de datele răzuite (CSV, JSON, Excel etc.) pentru a asigura compatibilitatea cu sistemele dvs. de procesare a datelor.
Caracteristici cheie de căutat
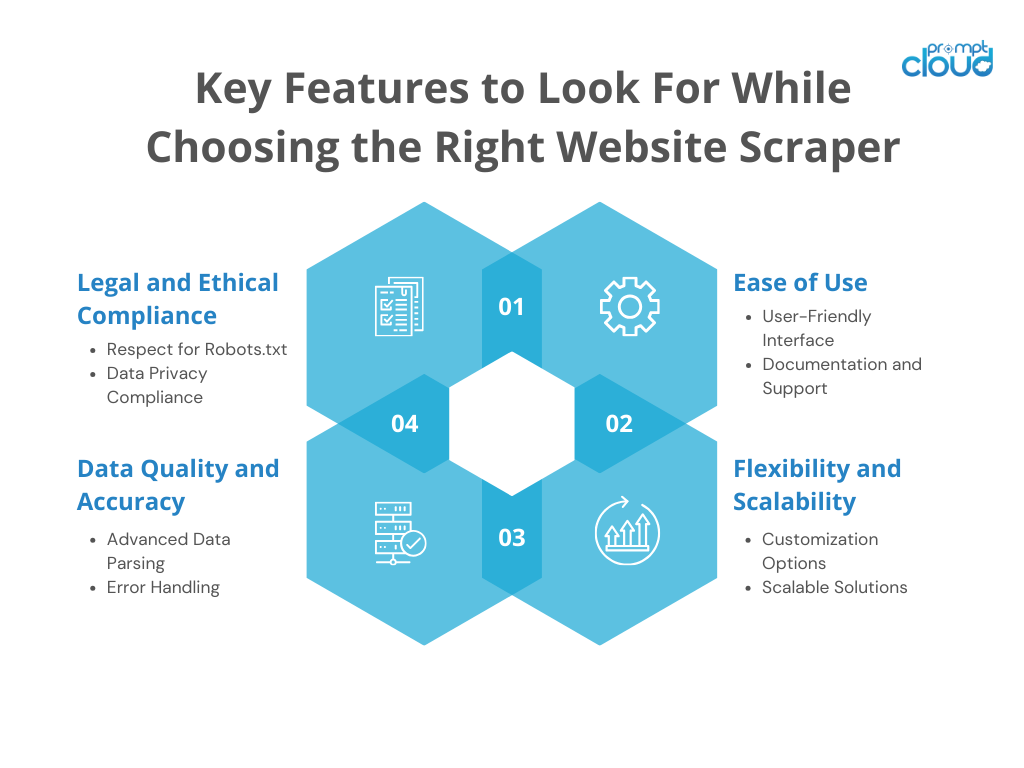
Ușurință în utilizare
- Interfață ușor de utilizat : Căutați instrumente cu interfețe intuitive care necesită expertiză tehnică minimă.
- Documentație și asistență : ghidurile cuprinzătoare și asistența pentru clienți receptivă vă pot îmbunătăți în mod semnificativ experiența de scraping.
Flexibilitate și scalabilitate
- Opțiuni de personalizare : Abilitatea de a vă personaliza activitățile de scraper web sau de scraping (anteturi, cookie-uri, sesiuni) este vitală pentru multe proiecte.
- Soluții scalabile : Asigurați-vă că instrumentul poate gestiona o creștere a volumului de date fără costuri suplimentare sau complexități semnificative.
Calitatea și acuratețea datelor
- Analiza avansată a datelor : instrumentele care oferă capabilități avansate de analizare pot extrage datele cu mai multă acuratețe.
- Gestionarea erorilor : Mecanismele robuste de gestionare a erorilor asigură integritatea datelor și reduc la minimum pierderile în timpul procesului de răzuire.
Conformitate legală și etică
- Respect pentru Robots.txt : instrumentele etice de răzuire a site-urilor web sau de răzuire respectă regulile stabilite în fișierele robots.txt ale site-urilor web.
- Conformitatea confidențialității datelor : este esențial să alegeți instrumente care respectă reglementările privind protecția datelor precum GDPR și CCPA.
Luând în considerare tipul de instrument de răzuire web
Open Source vs. Instrumente comerciale
- Instrumentele Open Source sunt adesea gratuite și personalizabile, dar ar putea necesita mai multe cunoștințe tehnice și o gestionare practică.
- Instrumentele comerciale oferă de obicei funcții mai cuprinzătoare, inclusiv asistență pentru clienți și opțiuni bazate pe cloud, potrivite pentru utilizatorii non-tehnici și operațiuni la scară largă.
DIY vs. Serviciu gestionat
- Instrumentele DIY vă oferă control deplin asupra procesului de răzuire, dar necesită timp și resurse pentru a le gestiona.
- Serviciile gestionate , precum PromptCloud, oferă soluții end-to-end în care toate aspectele tehnice sunt gestionate de experți, permițându-vă să vă concentrați pe analiza datelor.
Evaluarea instrumentelor potențiale
- Versiuni de probă : testați instrumentul cu o versiune de probă sau cu o versiune demonstrativă pentru a-i evalua capacitățile și ușurința de utilizare.
- Comunitate și recenzii : căutați feedback de la utilizatorii actuali pentru a evalua performanța și fiabilitatea instrumentului.
- Analiza costurilor : luați în considerare atât costurile inițiale, cât și cele continue în raport cu valoarea și calitatea datelor furnizate.
PromptCloud: Partenerul dvs. în Web Scraping
Alegerea corectă a site-ului web scraper sau a instrumentului de web scraping este doar începutul. La PromptCloud, oferim soluții cuprinzătoare de web scraping care răspund tuturor considerentelor de mai sus, asigurând servicii de extragere a datelor de înaltă calitate, scalabile și conforme din punct de vedere legal, adaptate nevoilor dvs. de afaceri.
Indiferent dacă doriți să culegeți informații despre piață, să monitorizați peisajele competitive sau să captați informații despre consumatori, echipa noastră de experți este aici pentru a vă ajuta să navigați în complexitățile web scraping și să deblocați întregul potențial al datelor web pentru afacerea dvs.
Sunteți gata să vă îmbunătățiți strategia de date cu PromptCloud? Contactați-ne astăzi pentru a descoperi cum soluțiile noastre personalizate de scraping web vă pot transforma eforturile de colectare a datelor. Luați legătura la [email protected]
Întrebări frecvente (FAQs)
1. Este legal să răzuiți web?
Legalitatea web scraping depinde în mare măsură de mai mulți factori, inclusiv de metodele utilizate pentru scraping, tipul de date care sunt colectate, modul în care sunt utilizate datele și condițiile specifice ale site-urilor web. Iată o defalcare detaliată:
Cadrul legal general
- Date publice vs. date private : în general, eliminarea informațiilor accesibile publicului fără a ocoli orice restricții tehnice (cum ar fi cerințele de conectare sau CAPTCHA) se încadrează într-o zonă gri din punct de vedere legal, dar este adesea considerată permisă. Cu toate acestea, eliminarea datelor private (date din spatele unei autentificări sau destinate anumitor utilizatori) fără permisiune poate duce la provocări legale.
- Termeni și condiții : multe site-uri web includ clauze în termenii și condițiile lor care interzic în mod explicit scrapingul web. Încălcarea acestor termeni poate duce la acțiuni legale în temeiul încălcării legilor contractuale, deși caracterul executoriu al acestor termeni este încă dezbătut în diferite jurisdicții.
- Legile drepturilor de autor : datele colectate prin scraping trebuie utilizate într-un mod care respectă legile drepturilor de autor. Reproducerea sau distribuirea de materiale protejate prin drepturi de autor fără autorizație poate duce la sancțiuni legale.
- Legile privind protecția datelor și confidențialitatea : Odată cu introducerea unor reglementări precum GDPR în Europa și CCPA în California, colectarea și utilizarea datelor cu caracter personal au devenit foarte reglementate. În cazul în care datele răzuite includ informații personale, este esențial să se asigure respectarea acestor legi pentru a evita amenzi mari și probleme legale.
Cazuri juridice notabile
Mai multe cazuri juridice au creat precedente în domeniul web scraping, cu rezultate diferite:

- hiQ Labs vs. LinkedIn : acest caz este adesea citat în discuțiile despre legalitatea web scraping. Instanța a decis în favoarea hiQ, permițându-le să colecteze date disponibile public de pe LinkedIn, indicând faptul că accesarea informațiilor publice online poate fi considerată legală.
Cele mai bune practici pentru web scraping legal
- Respectați Robots.txt : acest fișier de pe site-uri web indică ce părți ale unui site pot sau nu pot fi accesate cu crawlere de către roboți. Respectarea acestor reguli poate ajuta la evitarea problemelor juridice.
- Evitați supraîncărcarea serverelor : trimiterea prea multor solicitări într-o perioadă scurtă poate fi văzută ca un atac de tip denial of service, care duce la potențiale acțiuni legale.
- Căutați permisiunea atunci când aveți îndoieli : dacă nu sunteți sigur cu privire la legalitatea eliminării unui anumit site web, solicitarea permisiunii explicite de la proprietarul site-ului este cea mai sigură abordare.
Deși web scraping nu este în mod inerent ilegal, metodele folosite și tipul de date colectate pot influența legalitatea acesteia. Este esențial ca întreprinderile și persoanele fizice să ia în considerare implicațiile etice, să adere la standardele legale și să consulte consiliere juridică atunci când intenționează să elimini datele de pe web, în special atunci când se ocupă de materiale protejate prin drepturi de autor, date private sau site-uri web cu interdicții specifice privind răzuirea.
Această prezentare generală este destinată în scop informativ și nu trebuie luată ca un sfat juridic. Consultați-vă întotdeauna cu un profesionist juridic pentru a înțelege implicațiile web scraping în jurisdicția și cazul dvs. de utilizare.
2. Ce face scraping un site web?
Web scraping este procesul de utilizare a unui software automat pentru a extrage date și informații de pe site-uri web. Această tehnică simulează navigarea unui om prin web, folosind un program pentru a prelua conținut de pe diverse pagini web. Funcționalitățile și implicațiile de bază ale web scraping includ:
Extragerea datelor
- Colectarea informațiilor : instrumentele de scraping web pot aduna text, imagini, videoclipuri și alte date afișate pe site-uri web.
- Preluare date structurate : Aceste instrumente pot organiza conținutul web nestructurat în date structurate, cum ar fi foi de calcul sau baze de date, făcându-l mai ușor de analizat și utilizat.
Automatizarea colectării datelor
- Eficiență și viteză : Web scraping automatizează sarcina laborioasă de copiere și lipire manuală a informațiilor de pe site-uri web, accelerând semnificativ colectarea și procesarea datelor.
- Actualizări regulate : poate fi programat să ruleze la intervale regulate, asigurându-se că datele colectate sunt actualizate și reflectă orice modificări de pe site.
Aplicații de Web Scraping
- Cercetare de piață : companiile folosesc web scraping pentru a culege date despre concurenți, tendințele pieței, strategiile de prețuri și sentimentele clienților.
- Monitorizare SEO : profesioniștii în domeniul SEO răzuiesc date web pentru a urmări clasarea cuvintelor cheie, profilurile de backlink și strategiile de conținut.
- Generarea de clienți potențiali : echipele de vânzări și de marketing culeg informațiile de contact și alte date relevante pentru a identifica clienții potențiali.
- Comerț electronic : comercianții cu amănuntul online colectează datele despre produse de pe site-urile web ale concurenței pentru compararea prețurilor și analiza pieței.
- Cercetare academică : cercetătorii scot date de pe web pentru diverse studii, analize și proiecte academice.
Considerații legale și etice
În timp ce web scraping este un instrument puternic pentru colectarea datelor, este esențial să navigați în considerentele legale și etice implicate. Aceasta include respectarea legilor privind drepturile de autor, respectarea termenilor de utilizare a site-ului web și luarea în considerare a reglementărilor privind confidențialitatea, în special atunci când se ocupă de date personale.
Web scraping este o metodă de automatizare a extragerii datelor web într-un format structurat, utilizată în diverse industrii în diverse scopuri, de la business intelligence la cercetare academică. Cu toate acestea, necesită o analiză atentă a liniilor directoare legale și etice pentru a asigura conformitatea și respectul pentru proprietatea conținutului web și confidențialitatea utilizatorilor.
3. Cum răzuiesc complet un site web?
Scrape-ul complet al unui site web implică mai mulți pași, de la planificarea și alegerea instrumentelor potrivite până la executarea scrape-ului și procesarea datelor. Iată un ghid cuprinzător pentru a crea un site web în deplină conformitate cu standardele legale și etice:
Definiți-vă obiectivele
- Identificați datele de care aveți nevoie : fiți clar despre informațiile pe care doriți să le extrageți (de exemplu, detalii despre produse, prețuri, articole).
- Determinați domeniul de aplicare : decideți dacă trebuie să răzuiți întregul site sau doar anumite secțiuni.
Verificați considerentele legale și etice
- Consultați site-ul robots.txt : acest fișier, care se găsește de obicei la website.com/robots.txt, prezintă ce părți ale site-ului pot fi accesate cu crawlere de către roboți.
- Înțelegeți Termenii și condițiile : asigurați-vă că scrapingul nu încalcă termenii site-ului.
- Luați în considerare legile privind confidențialitatea : fiți atenți la modul în care gestionați datele personale, respectând legile precum GDPR sau CCPA.
Alegeți instrumentele potrivite
- Selectare bazată pe complexitate : instrumentele variază de la simple extensii de browser pentru scraping la scară mică până la software sofisticat precum Scrapy pentru Python, care este potrivit pentru proiecte mai mari și mai complexe.
- Servicii bazate pe cloud : pentru sarcini extinse de scraping, luați în considerare utilizarea serviciilor de web scraping bazate pe cloud care gestionează rotația IP, rezolvarea CAPTCHA și extragerea datelor la scară.
Pregătiți-vă mediul de răzuire
- Instalați software-ul necesar : configurați instrumentul de scraping sau mediul de dezvoltare ales.
- Configurați setările : ajustați setările pentru rata de accesare cu crawlere, anteturi și proxy, dacă este necesar, pentru a imita comportamentul uman de navigare și pentru a evita blocarea.
Implementați logica de extracție a datelor
- Scrieți scriptul Scraping : dacă utilizați un instrument de programare, scrieți codul pentru a naviga pe site, selectați datele relevante și extrageți-l. Acordați atenție modificărilor structurii site-ului care vă pot afecta scriptul.
- Utilizați selectoare cu înțelepciune : utilizați selectoare CSS, XPath sau regex pentru a viza cu precizie datele.
Rulați Scraperul
- Testați la scară mică : inițial, rulați racleta pe un segment mic al site-ului pentru a vă asigura că funcționează corect.
- Monitorizați și ajustați : urmăriți performanța scraper-ului și faceți toate ajustările necesare pentru a rezolva paginarea, conținutul dinamic sau orice erori.
Post-procesarea datelor
- Curățați și formatați datele : procesați datele răzuite (de exemplu, eliminarea duplicatelor, formatarea datelor) pentru a vă asigura că sunt utilizabile și valoroase.
- Stocați datele în mod corespunzător : salvați datele într-un format structurat, cum ar fi CSV, JSON sau direct într-o bază de date.
Respectați limitele de rată și evitați supraîncărcarea serverelor
- Solicitări de accelerare : Limitați numărul de solicitări către un site web într-un anumit interval de timp pentru a evita copleșirea serverului sau interzicerea adresei dvs. IP.
Actualizări regulate și întreținere
- Adaptați-vă la modificări : site-urile web își schimbă adesea aspectul sau structura, ceea ce vă poate necesita să actualizați scripturile de scraping.
- Programați scrape-uri regulate : dacă aveți nevoie de informații actualizate, programați-vă scrape-urile să ruleze automat la intervale regulate.
Instrumente și biblioteci
- Bibliotecile Python : BeautifulSoup, Scrapy și Selenium sunt populare pentru scripturile personalizate.
- Extensii de browser : instrumente precum Web Scraper (Chrome) și Import.io oferă interfețe ușor de utilizat pentru sarcini simple de scraping.
- Servicii cloud : PromptCloud, Octoparse și ParseHub oferă servicii de scraping gestionate care se ocupă de proiecte de extragere a datelor la scară largă.
Rafinarea completă a unui site web necesită o planificare atentă, execuție și un management continuu, mai ales având în vedere implicațiile legale și etice. Urmând acești pași și folosind instrumentele potrivite, puteți colecta eficient datele de care aveți nevoie, respectând în același timp regulile site-ului sursă și confidențialitatea utilizatorilor. Amintiți-vă, cheia pentru succesul web scraping constă în a fi respectuos, etici și legale în practicile dvs. de colectare a datelor.
4. ChatGPT poate face web scraping?
Nu, ChatGPT nu poate efectua web scraping. ChatGPT este conceput pentru a genera text pe baza informațiilor pe care a fost instruit până la ultima actualizare din aprilie 2023. Nu are capacitatea de a accesa internetul în timp real, de a prelua date live de pe site-uri web sau de a interacționa cu paginile web. Pentru sarcinile web scraping, ar trebui să utilizați instrumente sau servicii dedicate web scraping, care sunt special concepute pentru extragerea datelor de pe site-uri web. Aceste instrumente pot varia de la scripturi personalizate scrise cu biblioteci web scraping în limbaje de programare precum Python, până la software specializat și servicii bazate pe cloud care gestionează procesul de scraping pentru dvs.