
Como escolher o raspador de site certo para suas necessidades
Publicados: 2024-02-06No mundo atual, orientado por dados, a capacidade de coletar informações da Web com eficiência pode proporcionar às empresas uma vantagem competitiva significativa. No entanto, com uma infinidade de ferramentas de web scraping disponíveis, selecionar a ferramenta certa para suas necessidades específicas pode ser uma tarefa difícil. Na PromptCloud, entendemos a importância de fazer uma escolha informada, por isso compilamos este guia completo para ajudá-lo a selecionar o raspador de site perfeito.
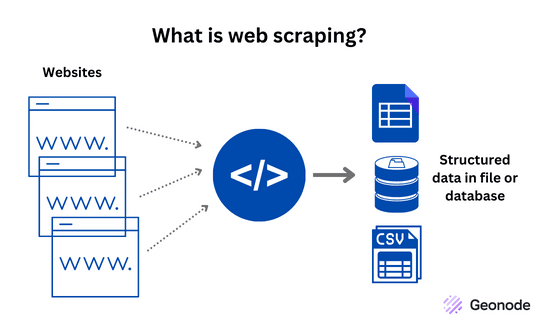
Fonte: https://geonode.com/blog/what-is-web-scraping
Compreendendo suas necessidades de raspagem
Antes de mergulhar no mar de ferramentas de raspagem, é crucial ter um entendimento claro de suas necessidades. Considere os seguintes fatores:
- Volume de dados : estime a quantidade de dados que você precisa extrair. Diferentes ferramentas são otimizadas para diversas escalas de extração de dados.
- Complexidade dos Sites : Alguns sites são mais complexos que outros, utilizando tecnologias como AJAX e JavaScript, o que pode complicar a extração de dados.
- Formato de dados : Determine em que formato você precisa dos dados extraídos (CSV, JSON, Excel, etc.) para garantir a compatibilidade com seus sistemas de processamento de dados.
Principais recursos a serem procurados
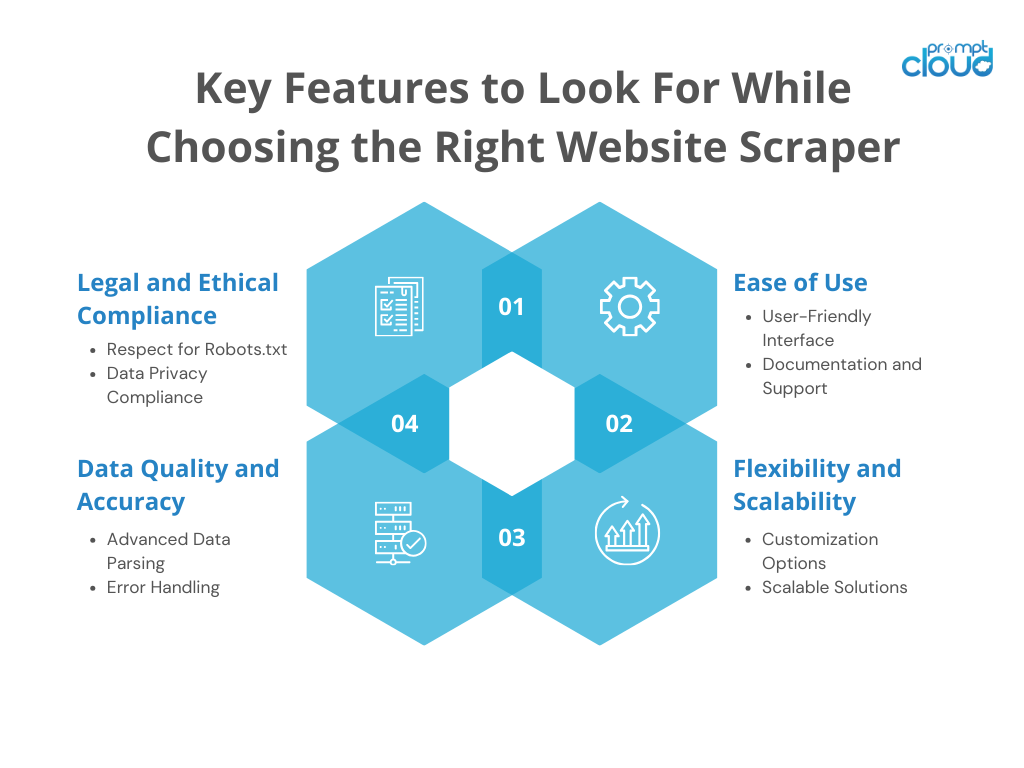
Fácil de usar
- Interface amigável : procure ferramentas com interfaces intuitivas que exijam conhecimento técnico mínimo.
- Documentação e suporte : guias abrangentes e suporte ao cliente ágil podem melhorar significativamente sua experiência de scraping.
Flexibilidade e escalabilidade
- Opções de personalização : A capacidade de personalizar seu web scraper ou tarefas de scraping (cabeçalhos, cookies, sessões) é vital para muitos projetos.
- Soluções escalonáveis : garanta que a ferramenta possa lidar com um aumento no volume de dados sem custos ou complexidades adicionais significativas.
Qualidade e precisão dos dados
- Análise avançada de dados : ferramentas que oferecem recursos avançados de análise podem extrair dados com mais precisão.
- Tratamento de erros : Mecanismos robustos de tratamento de erros garantem a integridade dos dados e minimizam as perdas durante o processo de raspagem.
Conformidade Legal e Ética
- Respeito pelo Robots.txt : o raspador ético de sites ou as ferramentas de raspagem seguem as diretrizes estabelecidas nos arquivos robots.txt dos sites.
- Conformidade com a privacidade de dados : é crucial escolher ferramentas que cumpram os regulamentos de proteção de dados, como GDPR e CCPA.
Considerando o tipo de ferramenta de web scraping
Código aberto vs. ferramentas comerciais
- As ferramentas de código aberto geralmente são gratuitas e personalizáveis, mas podem exigir mais conhecimento técnico e gerenciamento prático.
- As ferramentas comerciais normalmente oferecem recursos mais abrangentes, incluindo suporte ao cliente e opções baseadas em nuvem, adequadas para usuários não técnicos e operações em grande escala.
Faça você mesmo versus serviço gerenciado
- As ferramentas DIY oferecem controle total sobre o processo de raspagem, mas exigem tempo e recursos para serem gerenciadas.
- Os serviços gerenciados , como o PromptCloud, oferecem soluções ponta a ponta onde todos os aspectos técnicos são tratados por especialistas, permitindo que você se concentre na análise dos dados.
Avaliando ferramentas potenciais
- Versões de teste : teste a ferramenta com uma versão de teste ou demonstração para avaliar suas capacidades e facilidade de uso.
- Comunidade e avaliações : procure feedback dos usuários atuais para avaliar o desempenho e a confiabilidade da ferramenta.
- Análise de custos : considere os custos iniciais e contínuos em relação ao valor e à qualidade dos dados fornecidos.
PromptCloud: seu parceiro em web scraping
Escolher o raspador de site ou ferramenta de web scraping certo é apenas o começo. Na PromptCloud, fornecemos soluções abrangentes de web scraping que atendem a todas as considerações acima, garantindo serviços de extração de dados de alta qualidade, escalonáveis e legalmente compatíveis, adaptados às suas necessidades de negócios.
Esteja você procurando reunir inteligência de mercado, monitorar cenários competitivos ou capturar insights do consumidor, nossa equipe de especialistas está aqui para ajudá-lo a navegar pelas complexidades do web scraping e desbloquear todo o potencial dos dados da web para o seu negócio.
Pronto para elevar sua estratégia de dados com PromptCloud? Contate-nos hoje para descobrir como nossas soluções personalizadas de web scraping podem transformar seus esforços de coleta de dados. Entre em contato em [email protected]
Perguntas frequentes (FAQ)
1. É legal raspar a web?
A legalidade do web scraping depende em grande parte de vários fatores, incluindo os métodos usados para scraping, o tipo de dados coletados, como os dados são usados e os termos de serviço dos sites específicos. Aqui está uma análise detalhada:
Quadro Jurídico Geral
- Dados públicos versus dados privados : geralmente, a coleta de informações acessíveis ao público sem contornar quaisquer restrições técnicas (como requisitos de login ou CAPTCHA) cai em uma área legalmente cinzenta, mas muitas vezes é considerada permitida. No entanto, a extração de dados privados (dados por trás de um login ou destinados a usuários específicos) sem permissão pode levar a desafios legais.
- Termos de serviço : muitos sites incluem cláusulas em seus termos de serviço que proíbem explicitamente a web scraping. A violação destes termos pode potencialmente levar a ações legais por violação das leis contratuais, embora a aplicabilidade de tais termos ainda seja debatida em várias jurisdições.
- Leis de direitos autorais : Os dados coletados por meio de scraping devem ser usados de forma que respeite as leis de direitos autorais. A reprodução ou distribuição de material protegido por direitos autorais sem autorização pode resultar em penalidades legais.
- Leis de proteção de dados e privacidade : Com a introdução de regulamentações como o GDPR na Europa e a CCPA na Califórnia, a coleta e o uso de dados pessoais tornaram-se altamente regulamentados. Se os dados extraídos incluírem informações pessoais, é essencial garantir o cumprimento dessas leis para evitar multas pesadas e questões legais.
Casos jurídicos notáveis
Vários casos legais estabeleceram precedentes no domínio do web scraping, com resultados variados:

- hiQ Labs x LinkedIn : Este caso é frequentemente citado em discussões sobre a legalidade do web scraping. O tribunal decidiu a favor da hiQ, permitindo-lhes extrair dados publicamente disponíveis do LinkedIn, indicando que o acesso a informações públicas online pode ser considerado legal.
Melhores práticas para raspagem legal da Web
- Siga Robots.txt : este arquivo em sites indica quais partes de um site podem ou não ser rastreadas por bots. Respeitar essas regras pode ajudar a evitar problemas jurídicos.
- Evite sobrecarregar servidores : enviar muitas solicitações em um curto período pode ser visto como um ataque de negação de serviço, levando a possíveis ações legais.
- Procure permissão em caso de dúvida : se não tiver certeza sobre a legalidade de copiar um site específico, solicitar permissão explícita do proprietário do site é a abordagem mais segura.
Embora o web scraping não seja inerentemente ilegal, os métodos empregados e o tipo de dados coletados podem influenciar sua legalidade. É crucial que empresas e indivíduos considerem as implicações éticas, cumpram os padrões legais e consultem aconselhamento jurídico ao planejarem extrair dados da Web, especialmente ao lidar com materiais protegidos por direitos autorais, dados privados ou sites com proibições específicas de extração.
Esta visão geral destina-se a fins informativos e não deve ser considerada como aconselhamento jurídico. Sempre consulte um profissional jurídico para entender as implicações do web scraping em sua jurisdição e caso de uso.
2. O que a raspagem de um site faz?
Web scraping é o processo de uso de software automatizado para extrair dados e informações de sites. Essa técnica simula a navegação de um ser humano pela web, utilizando um programa para recuperar conteúdo de diversas páginas web. As principais funcionalidades e implicações do web scraping incluem:
Extração de dados
- Coletando informações : as ferramentas de web scraping podem coletar textos, imagens, vídeos e outros dados exibidos em sites.
- Recuperação de dados estruturados : essas ferramentas podem organizar o conteúdo não estruturado da web em dados estruturados, como planilhas ou bancos de dados, facilitando a análise e o uso.
Automação de coleta de dados
- Eficiência e velocidade : Web scraping automatiza a trabalhosa tarefa de copiar e colar manualmente informações de sites, acelerando significativamente a coleta e o processamento de dados.
- Atualizações Regulares : Pode ser programado para ser executado em intervalos regulares, garantindo que os dados coletados estejam atualizados e refletindo quaisquer alterações no site.
Aplicações de Web Scraping
- Pesquisa de mercado : as empresas usam web scraping para coletar dados sobre concorrentes, tendências de mercado, estratégias de preços e sentimentos dos clientes.
- Monitoramento de SEO : os profissionais de SEO coletam dados da web para rastrear classificações de palavras-chave, perfis de backlinks e estratégias de conteúdo.
- Geração de leads : as equipes de vendas e marketing coletam informações de contato e outros dados relevantes para identificar clientes em potencial.
- Comércio eletrônico : os varejistas on-line coletam dados de produtos de sites concorrentes para comparação de preços e análise de mercado.
- Pesquisa Acadêmica : Os pesquisadores extraem dados da web para vários estudos, análises e projetos acadêmicos.
Considerações Legais e Éticas
Embora o web scraping seja uma ferramenta poderosa para coleta de dados, é essencial navegar pelas considerações legais e éticas envolvidas. Isto inclui respeitar as leis de direitos autorais, aderir aos termos de uso do site e considerar as regulamentações de privacidade, especialmente ao lidar com dados pessoais.
Web scraping é um método para automatizar a extração de dados da web em um formato estruturado, usado em vários setores para diversos fins, desde inteligência de negócios até pesquisa acadêmica. No entanto, exige uma análise cuidadosa das diretrizes legais e éticas para garantir a conformidade e o respeito pela propriedade do conteúdo da Web e pela privacidade do usuário.
3. Como faço para raspar completamente um site?
A raspagem completa de um site envolve várias etapas, desde o planejamento e escolha das ferramentas certas até a execução da raspagem e o processamento dos dados. Aqui está um guia completo para raspar um site com eficácia, em total conformidade com os padrões legais e éticos:
Defina seus objetivos
- Identifique os dados que você precisa : seja claro sobre quais informações você deseja extrair (por exemplo, detalhes de produtos, preços, artigos).
- Determine o escopo : decida se você precisa copiar todo o site ou apenas seções específicas.
Verifique as considerações legais e éticas
- Revise o robots.txt do site : esse arquivo, normalmente encontrado em website.com/robots.txt, descreve quais partes do site podem ser rastreadas por bots.
- Entenda os Termos de Serviço : certifique-se de que a raspagem não viole os termos do site.
- Considere as leis de privacidade : esteja atento à forma como você lida com dados pessoais, respeitando leis como GDPR ou CCPA.
Escolha as ferramentas certas
- Seleção baseada na complexidade : as ferramentas variam de simples extensões de navegador para raspagem em pequena escala até softwares sofisticados como o Scrapy para Python, que é adequado para projetos maiores e mais complexos.
- Serviços baseados em nuvem : para tarefas extensas de scraping, considere o uso de serviços de web scraping baseados em nuvem que gerenciam a rotação de IP, resolução de CAPTCHA e extração de dados em escala.
Prepare seu ambiente de raspagem
- Instale o software necessário : Configure a ferramenta de scraping ou ambiente de desenvolvimento escolhido.
- Definir configurações : ajuste as configurações de taxa de rastreamento, cabeçalhos e proxies, se necessário, para imitar o comportamento de navegação humano e evitar bloqueios.
Implementar lógica de extração de dados
- Escreva o script de raspagem : se estiver usando uma ferramenta de programação, escreva o código para navegar no site, selecione os dados relevantes e extraia-os. Preste atenção às alterações na estrutura do site que podem afetar seu script.
- Use seletores com sabedoria : utilize seletores CSS, XPath ou regex para direcionar os dados com precisão.
Execute o raspador
- Teste em pequena escala : inicialmente, execute seu raspador em um pequeno segmento do site para garantir que funcione corretamente.
- Monitore e ajuste : fique de olho no desempenho do scraper e faça os ajustes necessários para lidar com paginação, conteúdo dinâmico ou quaisquer erros.
Pós-processamento de dados
- Limpe e formate dados : processe os dados copiados (por exemplo, removendo duplicatas, formatando datas) para garantir que sejam utilizáveis e valiosos.
- Armazene os dados de maneira adequada : salve os dados em um formato estruturado, como CSV, JSON ou diretamente em um banco de dados.
Respeite os limites de taxa e evite sobrecarregar os servidores
- Solicitações de aceleração : limite o número de solicitações para um site dentro de um determinado período para evitar sobrecarregar o servidor ou banir seu endereço IP.
Atualizações e manutenção regulares
- Adapte-se às mudanças : os sites geralmente mudam seu layout ou estrutura, o que pode exigir que você atualize seus scripts de scraping.
- Agendar scrapes regulares : se você precisar de informações atualizadas, programe seus scrapes para serem executados automaticamente em intervalos regulares.
Ferramentas e bibliotecas
- Bibliotecas Python : BeautifulSoup, Scrapy e Selenium são populares para scripts personalizados.
- Extensões de navegador : ferramentas como Web Scraper (Chrome) e Import.io oferecem interfaces fáceis de usar para tarefas simples de raspagem.
- Serviços em nuvem : PromptCloud, Octoparse e ParseHub fornecem serviços gerenciados de scraping que lidam com projetos de extração de dados em grande escala.
A eliminação completa de um site requer planejamento, execução e gerenciamento contínuos cuidadosos, especialmente considerando as implicações legais e éticas. Seguindo essas etapas e usando as ferramentas certas, você pode coletar com eficiência os dados necessários, respeitando as regras do site de origem e a privacidade do usuário. Lembre-se de que a chave para um web scraping bem-sucedido está em ser respeitoso, ético e legal em suas práticas de coleta de dados.
4. O ChatGPT pode fazer web scraping?
Não, o ChatGPT não pode realizar web scraping. O ChatGPT foi projetado para gerar texto com base nas informações nas quais foi treinado até sua última atualização em abril de 2023. Ele não tem a capacidade de acessar a Internet em tempo real, recuperar dados ao vivo de sites ou interagir com páginas da web. Para tarefas de web scraping, você precisaria usar ferramentas ou serviços dedicados de web scraping projetados especificamente para extrair dados de sites. Essas ferramentas podem variar de scripts personalizados escritos com bibliotecas de web scraping em linguagens de programação como Python, até software especializado e serviços baseados em nuvem que gerenciam o processo de scraping para você.