
Ładowanie spekulacyjne jest dostępne w WordPress
Opublikowany: 2024-04-18Podczas naszego seminarium internetowego na temat „Natychmiastowego ładowania stron” na początku 2024 r. Adam Silverstein z Google wspomniał, że zespół WordPress ds. wydajności pracuje nad wtyczką, która umożliwi interfejs API reguł spekulacji:
Przejdźmy szybko do kwietnia 2024 r., kiedy WordPress oficjalnie wypuścił Speulative Loading, wtyczkę wydajnościową obsługującą interfejs API reguł spekulacji.

Ale zanim do tego przejdziemy, oto krótki przegląd interfejsu API reguł spekulacji.
Wyjaśnienie API reguł spekulacji
Poniższe akapity zawierają zwięzłe wyjaśnienie interfejsu API reguł spekulacji firmy Google. Jeśli chcesz zagłębić się w szczegóły,przeczytaj nasz dedykowany artykuł.
Speculation Rules API to eksperymentalna technologia opracowana przez Google w celu poprawy wydajności przyszłych nawigacji na stronach. Opierając się na powszechnie dostępnych wskazówkach dotyczących zasobów link rel=prefetchil ink rel=prerender, ten interfejs API zdefiniowany w formacie JSON zapewnia programistom i właścicielom witryn bardziej elastyczny i wyrazisty sposób określania, które dokumenty powinny zostać pobrane z wyprzedzeniem lub wstępnie wyrenderowane.
Możesz łatwo ustawić spekulacyjny typ ładowania (wstępne pobieranie lub wstępne renderowanie) wewnątrz pliku elementy i zewnętrzne pliki tekstowe, do których odwołuje się nagłówek odpowiedzi Speculation-Rules.
Masz dwie możliwości włączenia interfejsu API reguł spekulacji:
- Użyj wzorców adresów URL: zdefiniuj, które adresy URL mogą być pobierane z wyprzedzeniem lub wstępnie renderowane.
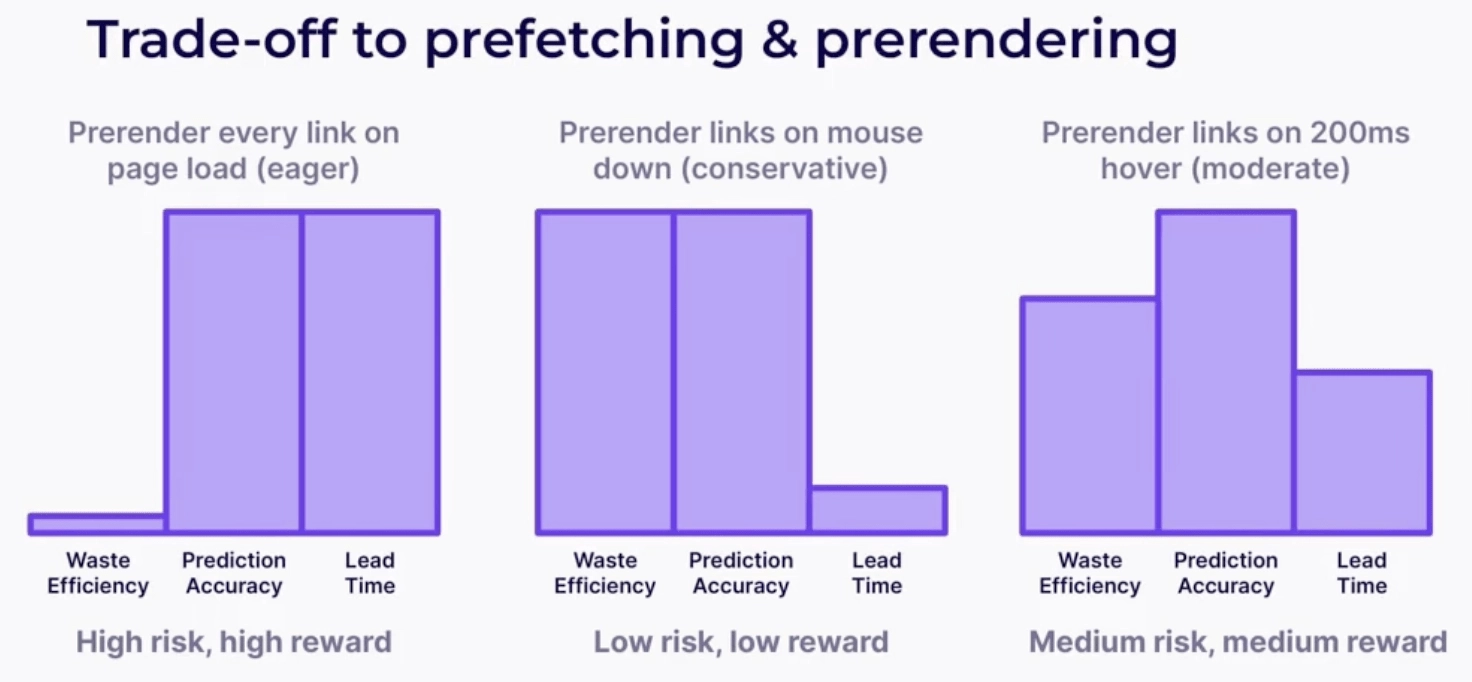
- Określ poziom „zapału”: Użyj ustawieniazapału, aby wskazać, kiedy powinny zostać uruchomione spekulacje – „chęć” uruchamia zasady spekulacji, gdy tylko zostaną zaobserwowane; „umiarkowany” wykonuje spekulacje, jeśli najedziesz kursorem na łącze na 200 milisekund; „konserwatysta” spekuluje na temat wskaźnika lub dotknięcia

Jak określić poziom „zapału”
To, czy chcesz wstępnie pobrać, czy wstępnie renderować stronę, zależy od tego, jaką poprawę wydajności chcesz osiągnąć:
Prefetch instruuje przeglądarkę, aby pobrała treść odpowiedzi odnośnych stron, ale nie podzasoby, do których odwołuje się strona. Gdy użytkownik przejdzie do wstępnie pobranej strony, ładuje się ona szybciej niż zwykle.
Z drugiej stronyfunkcja wstępnego renderowania instruuje przeglądarkę, aby pobrała, wyrenderowała i załadowała całą zawartość, w tym zasoby podrzędne i kod JavaScript, do niewidocznej karty.To wstępne ładowanie zasobów powoduje, że użytkownik przechodzi na stronę niemal natychmiastowo.
Chociaż korzyści w zakresie wydajności wynikające z wstępnego renderowania są bardziej znaczące, tej technologii ładowania należy używać oszczędnie. Wstępne renderowanie zużywa dużo pamięci i przepustowości sieci, co może prowadzić do marnowania zasobów, jeśli użytkownik nie przejdzie do strony.
I odwrotnie, początkowy koszt pobierania wstępnego jest znacznie niższy niż koszt wstępnego renderowania, więc pobieranie wstępne można zastosować szerzej.
Wstępne renderowanie i pobieranie wstępne w WordPress
Użytkownicy WordPressa mogą od lat wstawiać znaczniki linków w celu wstępnego pobierania lub wstępnego renderowania zasobów w dokumentach HTML dzięki interfejsowi Resource Hints API.
Jednak użycie tagów jest mało elastyczne, ponieważ adresy URL muszą zostać określone wcześniej, co prowadzi do potencjalnego marnotrawstwa zasobów lub utraty wydajności. Co więcej, rozwiązania dynamiczne, które wstawiają znaczniki łączy w oparciu o widoczność w rzutni, oferują większą elastyczność, ale nadal mogą prowadzić do nadmiernego pobierania z wyprzedzeniem.
Biorąc pod uwagę wszystkie te ograniczenia, zespół ds. wydajności był bardzo zmotywowany do znalezienia lepszego rozwiązania…
Ładowanie spekulatywne: nowa wtyczka wydajnościowa WordPress
Ładowanie spekulatywne umożliwia wstępne renderowanie lub wstępne pobieranie innych adresów URL frontendu, do których prowadzą linki na stronie.
Po aktywacji wtyczka automatycznie wstawia skrypt JSON i wstępnie renderuje dowolne adresy URL na stronie z „umiarkowanym” zapałem.
Możesz łatwo zmienić to domyślne zachowanie i zmodyfikować je w sekcji „Ładowanie spekulacyjne” na ekranie Ustawienia > Czytanie :


Źródło:WordPress
Ponadto możesz dostosować, które adresy URL mają być wstępnie ładowane spekulacyjnie, korzystając z filtra o nazwie „plsr_speculation_rules_href_exclude_paths”. Na przykład strony zmodyfikowane na podstawie działań użytkownika (np. koszyk) można wykluczyć z wstępnego renderowania lub pobierania.
Oto przykładowy kod filtra:

Źródło:WordPress
Jak testować i wysyłać opinie
Zespół WordPress ds. wydajności zachęca więcej osób do przetestowania nowej wtyczki, ponieważ rozważają włączenie tej funkcji do rdzenia WordPress w przyszłości.
Oto jak możesz im pomóc:
- Zainstaluj i aktywuj wtyczkę Speulative Loading na swojej stronie za pośrednictwem WP Admin lub wtyczki Performance Lab.
- Wypróbuj różne konfiguracje w sekcji „Ładowanie spekulatywne” w obszarze Ustawienia > Czytanie.
- Debuguj, w jaki sposób reguły dodane przez wtyczkę uruchamiają ładowanie spekulacyjne, aby lepiej zrozumieć funkcję i znaleźć potencjalne błędy.
- Zgłaszaj opinie lub błędy w repozytorium GitHub lub na forach wsparcia wtyczki.
- Zintegruj swoje wtyczki z filtrem „plsr_speculation_rules_href_exclude_paths”, aby wykluczyć określone adresy URL z pobierania wstępnego i/lub wstępnego renderowania.
Nawigacja AI firmy NitroPack: zautomatyzowane rozwiązanie umożliwiające błyskawiczne przeglądanie stron
Nawigacja AI firmy NitroPack to oparty na sztucznej inteligencji optymalizator wydajności sieci, który automatycznie przewiduje i analizuje zachowania użytkowników, aby wstępnie renderować całe strony podczas podróży klienta.
Opierając się na interfejsie API reguł spekulacji, to rozwiązanie bezdotykowe umożliwia programistom i właścicielom witryn zapewnianie natychmiastowego przeglądania poprzez:
- Stosowanie wspomaganych przez sztuczną inteligencję wstępnych przewidywań dotyczących ładowania strony na podstawie danych bez przekazywania ich do interfejsu API reguł spekulacji (jeszcze);
- Analizowanie zachowań użytkowników, dostosowywanie przewidywań i instruowanie interfejsu API reguł spekulacji, aby wstępnie renderował (lub pobierał z wyprzedzeniem) stronę, gdy mamy pewność, jakie będzie następujące działanie.

To połączenie sztucznej inteligencji i interfejsu API reguł spekulacji Google nieuchronnie prowadzi do imponujących wyników w zakresie wydajności:
- Czas ładowania poniżej 3 sekund.
- Ogromne ulepszenia w LCP (największa farba treściowa) i CLS (skumulowana zmiana układu)
- Lepsze podstawowe wskaźniki internetowe dla całej witryny
Jeśli więc chcesz, aby Twoi odwiedzający byli zachwyceni szybkością ładowania się Twoich stron…
Dołącz do listy oczekujących na Nawigację AI i przygotuj swoją witrynę na natychmiastowe doświadczenia użytkowników →
Często zadawane pytania
Czy wtyczka Speculative Loading w WordPressie korzysta z sztucznej inteligencji?
Nie, wtyczka Speculative Loading nie jest obsługiwana przez sztuczną inteligencję (AI). Wykorzystuje interfejs API reguł spekulacji Google, wstawiając skrypt JSON do dowolnych adresów URL, do których prowadzą linki na stronie, i wstępnie je renderując z konfiguracją gotowości „umiarkowaną”.
Które strony kwalifikują się do ładowania spekulacyjnego?
Możesz zastosować strategie ładowania spekulatywnego do wszystkich stron, które nie są modyfikowane przez działania użytkownika. Dobrą zasadą jest unikanie wstępnego renderowania lub wstępnego pobierania stron realizacji transakcji i koszyka, ponieważ może to pogorszyć komfort użytkownika. Ponadto Google zaleca tylko strony pozorowane, gdy istnieje duże prawdopodobieństwo (ponad 80% przypadków), że użytkownicy je załadują.
Które przeglądarki obsługują API reguł spekulacji?
Chociaż interfejs Speculation Rules API jest dostępny w przeglądarkach Chrome i Edge od wersji 109, konkretna podfunkcja „reguły dokumentu”, która pozwala przeglądarce uzyskać listę adresów URL do spekulatywnego ładowania z elementów strony, jest dostępna w przeglądarce Chrome 121. Innymi słowy, użytkownicy będą musieli używać przeglądarki Chrome 121+ lub Edge 121+, aby w pełni korzystać z interfejsu Speculation Rules API.
W jaki sposób Google Analytics radzi sobie ze wstępnym ładowaniem spekulacyjnym?
Jeśli korzystasz z Google Analytics, nie musisz nic robić, ponieważ GA domyślnie obsługuje prerenderowanie opóźniając do momentu aktywacji. Jednak w przypadku innych narzędzi wstępnie renderowane strony mogą mieć wpływ na statystyki, a właściciele witryn mogą potrzebować dodać dodatkowy kod, aby po aktywacji włączyć analizę tylko dla wstępnie renderowanych stron. Można to osiągnąć za pomocą obietnicy, która czeka na zdarzenie prerenderingchange , jeśli dokument jest wstępnie renderowany.