
Jak używać interfejsu API reguł spekulacji do natychmiastowego ładowania stron internetowych
Opublikowany: 2024-02-17Rok 2024 zapowiada się na czas, w którym natychmiastowe ładowanie stanie się nowym standardem wydajności sieci, a wszyscy właściciele firm internetowych będą słuchać.
Jednak prace nad przejściem z trybu szybkiego na natychmiastowe trwają już od jakiegoś czasu.
Już w 2009 roku dążenie do szybszego i wydajniejszego ładowania stron skłoniło zespół Chromium do stworzenia pierwszych podpowiedzi do zasobów, do których później dodano link rel=”prerender”.
Oczekiwano, że będzie to miało znaczący wpływ na wydajność, ponieważ wymagało ładowania kolejnych stron w tle, zanim użytkownik do nich przejdzie, zapewniając szybsze renderowanie po wystąpieniu przejścia.
Jednak ta wersja wstępnego renderowania nie okazała się wystarczająco wydajna i została wycofana w 2017 roku.
Przejdźmy do dzisiejszego dnia: Google wprowadził obiecujące ulepszenia swojego interfejsu API Speculation Rules, umożliwiając bardziej wyrafinowane podejście do pełnego wstępnego renderowania i odblokowywania naprawdę płynnego przeglądania sieci.
Co to jest interfejs API reguł spekulacji firmy Google?
Interfejs API reguł spekulacyjnych to interfejs API zdefiniowany w formacie JSON opracowany przez firmę Google w celu zwiększenia wydajności ładowania stron internetowych za pomocą strategii ładowania spekulacyjnego.
Ładowanie spekulatywne polega na przewidywaniu i wstępnym ładowaniu zasobów na potrzeby kolejnych nawigacji na stronach, co prowadzi do szybszego renderowania i poprawy komfortu użytkownika. Firma Google wprowadziła ten interfejs API, aby zapewnić programistom bardziej elastyczny i ekspresyjny sposób określania, które dokumenty powinny być pobierane z wyprzedzeniem, a które wstępnie renderowane.
Kluczowe szczegóły dotyczące interfejsu API reguł spekulacji:
- Kierowanie na adresy URL dokumentów: w przeciwieństwie do tradycyjnych mechanizmów pobierania z wyprzedzeniem, które celują w określone pliki zasobów, interfejs API reguł spekulacji skupia się na adresach URL dokumentów. Dzięki temu jest szczególnie odpowiedni do aplikacji wielostronicowych (MPA), a nie aplikacji jednostronicowych (SPA).
- Wstępne renderowanie i pobieranie wstępne: interfejs API obsługuje zarówno strategie wstępnego renderowania, jak i pobierania wstępnego. Wstępne renderowanie obejmuje pobieranie, renderowanie i ładowanie treści do niewidocznej karty, gotowej do niemal natychmiastowej aktywacji, gdy użytkownik przejdzie na stronę. Z drugiej strony pobieranie wstępne pobiera i zapisuje określone zasoby strony (np. dokument, obraz, skrypt itp.), optymalizując czas ładowania, gdy użytkownik później przejdzie do tych stron.
- Obsługa przeglądarek: interfejs API jest obecnie kompatybilny ze wszystkimi przeglądarkami opartymi na Chromium, w tym Chrome, Edge, Opera, Chrome Android, Opera Android i WebView Android. Pełne zestawienie kompatybilności znajdziesz w dokumentacji Mozilli:

Możesz także sprawdzić, czy przeglądarki obsługują API za pomocą następującego kodu:

- Alternatywa dla przestarzałych funkcji: stanowi alternatywę dla starszych technologii, takich jak przestarzała funkcja dostępna tylko w przeglądarce Chrome , oferując lepszą wydajność i bardziej wyrazistą składnię.
- Względy bezpieczeństwa: wstępne pobieranie między witrynami ma ograniczenia mające na celu ochronę prywatności użytkowników. Pobieranie wstępne między witrynami działa tylko wtedy, gdy użytkownik nie ma ustawionych plików cookie dla witryny docelowej, co uniemożliwia potencjalne śledzenie aktywności użytkownika.
Dlaczego warto używać interfejsu API reguł spekulacji w swojej witrynie?
Interfejs API reguł spekulacji umożliwianiemal natychmiastowe ładowanie stron, zapewniając bezproblemowe przeglądanie.
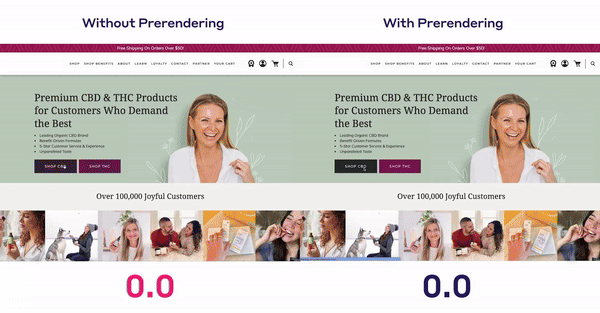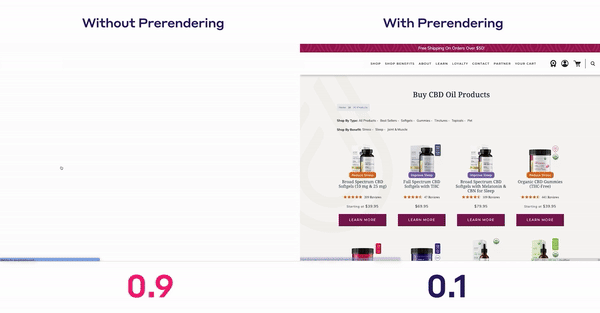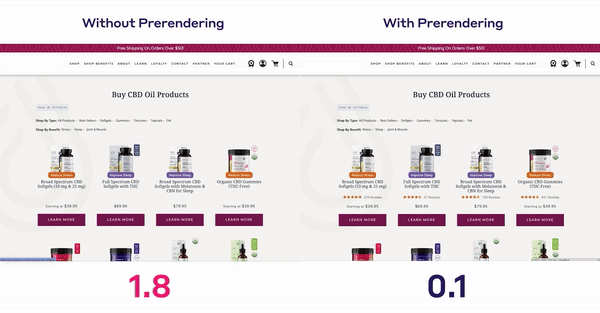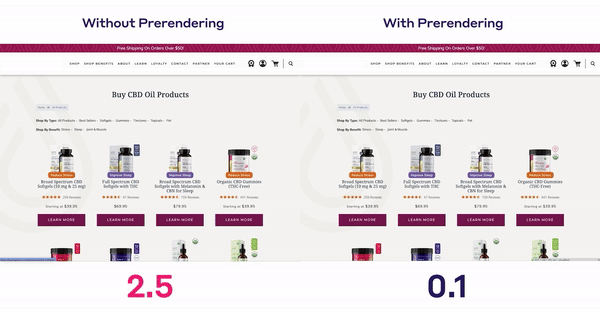
Krótszy czas ładowania strony,większa satysfakcja użytkowników i potencjalne korzyści związane z SEOto istotne powody, dla których programiści wybierają tę technologię.
Zmniejszając opóźnienia między nawigacjami stron, użytkownicy postrzegają witrynę jako bardziej płynną i responsywną. Staje się to wyraźnie widoczne wpodstawowych wskaźnikach internetowych Twojej witryny, gdzie wielkość największej zawartości treści (LCP), skumulowane przesunięcie układu (CLS) i interakcja z następną farbą (INP) drastycznie spadają.
Natychmiastowe przeglądanie wiąże się z niższym współczynnikiem odrzuceń i większym utrzymaniem użytkowników– to istotne wskaźniki sukcesu Twojej platformy internetowej. W ten sposób podkreślamy strategiczną wartość integracji API reguł spekulacji.
Jak działa API reguł spekulacji?
Interfejs API reguł spekulacyjnych Google został zaprojektowany tak, aby kierować reklamy na adresy URL dokumentów, a nie na określone pliki zasobów. Interfejs API reguł spekulacji wprowadza bardziej wyrazistą i konfigurowalną składnię służącą do określania, które dokumenty powinny być pobierane z wyprzedzeniem, a które wstępnie renderowane.
Dzięki strukturze zdefiniowanej w formacie JSON w skrypcie type="speculationrules" programiści mogą formułować reguły zarówno dotyczące wstępnego renderowania, jak i pobierania z wyprzedzeniem. Ta zwiększona elastyczność pozwala na precyzyjne dostrojenie ładowania spekulacyjnego.
Niedawno firma Google ogłosiła nowe ulepszenie interfejsu API reguł spekulacji w przeglądarce Chrome 121, które zapewnia teraz opcję automatycznego wyszukiwania linków.

Odbywa się to poprzez:
- Określanie źródła dokumentu
- Wybieranie linków na stronie w oparciu o adresy URL lub selektory CSS
- Określenie poziomu „zapału” – chętny (od razu), umiarkowany (po najechaniu myszką na 200 ms) i konserwatywny (po najechaniu myszką lub dotknięciu)
Jeśli jednak dopiero zaczynasz korzystać z interfejsu Speculation Rules API, zalecamy najpierw przetestowanie różnych konfiguracji przedstawionych poniżej.
Jak korzystać z interfejsu API reguł spekulacji Google
Interfejs API reguł spekulacji umożliwia programistom stosowanie ustrukturyzowanego podejścia do optymalizacji procesów wstępnego renderowania i pobierania wstępnego.
Organizować coś
Rozpoczyna się od utworzenia elementu skryptu type="speculationrules" i zdefiniowania w nim reguł spekulacji w strukturze JSON.
Reguły spekulacji można dodać zarówno w nagłówku, jak i w treści głównej klatki.
Ważne: reguły spekulacji w ramkach podrzędnych nie są uwzględniane, a reguły spekulacji na wstępnie renderowanych stronach są uwzględniane dopiero wtedy, gdy użytkownik przejdzie do samej strony.
Reguły spekulacji można uwzględnić statycznie lub dynamicznie.
- Konfiguracja statyczna odbywa się w kodzie HTML strony (idealna dla witryn, w których następne działanie jest pewne, np. witryna z wiadomościami może chcieć wstępnie wyrenderować najważniejsze wydarzenie dnia)
- Konfiguracja dynamiczna odbywa się za pomocą JavaScript (odpowiednia dla witryn internetowych, w których często używane są spersonalizowane doświadczenia użytkowników)

Ważne: Decydując się na konfigurację dynamiczną, zawsze odsyłaj do dokumentacji pomocy technicznej w celu uzyskania informacji na temat przyszłych zmian i przypadków użycia, które mogą stać się dostępne w przyszłości.
Aby poinformować przeglądarkę, które adresy URL mają byćwstępnie renderowane , możesz wstawić na swoich stronach instrukcje JSON:

Podobnie wstaw następujące instrukcje JSON dotyczące pobierania wstępnego :

Do strony można dodać wiele reguł spekulacji. W takim przypadku należy poinstruować przeglądarkę na dowolnym z poniższych poziomów:
- Lista adresów URL
- Wiele zasad spekulacji
- Wiele list w ramach jednego zestawu reguł spekulacyjnych
Określanie tras wstępnego renderowania/wstępnego pobierania
Dostrajanie ładowania spekulatywnego obejmuje określenie tras do wstępnego renderowania i wstępnego pobierania. Kategoryzując strony na podstawie ich znaczenia lub prawdopodobieństwa nawigacji użytkownika, programiści mogą zoptymalizować strategię ładowania spekulatywnego.
Istnieją jednak pewne trasy uważane za niebezpieczne, takie jak:
- Adresy URL wylogowania;
- Adresy URL zmiany języka;
- Adresy URL „Dodaj do koszyka”;
- Adresy URL przepływu logowania, pod którymi serwer żąda wysłania wiadomości SMS, np. gdy potrzebne jest uwierzytelnianie dwuskładnikowe (2FA);
- Adresy URL inicjujące śledzenie konwersji reklam po stronie serwera;
- Adresy URL, które uruchamiają limity użytkowania użytkownika, na przykład poprzez wykorzystanie miesięcznego limitu bezpłatnych artykułów.
Podobnie jak w przypadku wykluczania takich stron z buforowania, powodem unikania ich wstępnego pobierania i renderowania jest związek ze zmiennymi dynamicznymi.

Są to strony wrażliwe na treść, których wartości są aktualizowane w oparciu o działania użytkownika, a wstępne ładowanie ich w tle powoduje, że ryzyko wyświetlenia nieaktualnego stanu strony jest bardzo wysokie.
Dokładność i kompromisy
Jak wspomniał Barry Pollard podczas naszego seminarium internetowego na temat „Natychmiastowego ładowania stron”:
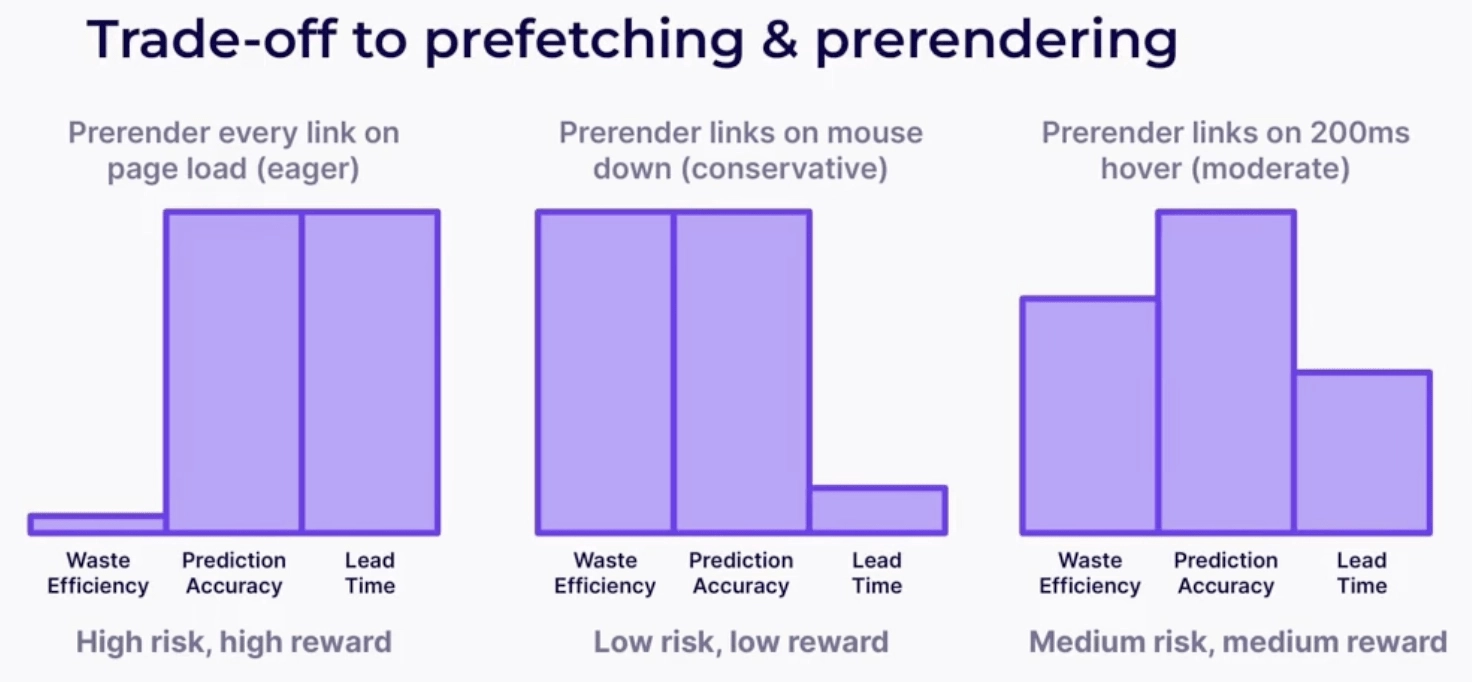
Chociaż pobieranie z wyprzedzeniem jest najbezpieczniejszą metodą, którą możesz powielić na wielu stronach internetowych, oferuje również najniższą nagrodę, ponieważ obejmuje tylko pobranie określonych zasobów.
Z drugiej strony, pełnostronicowe renderingi wstępne oferują wyższe nagrody, ale należy ich używać oszczędnie, ponieważ mogą:
- Przytłacza przeglądarkę, ponieważ może ona uruchamiać w tle tylko ograniczoną liczbę zadań.
- Zużywają znaczną przepustowość i zasoby procesora, co może prowadzić do pogorszenia wydajności użytkowników w wolniejszych sieciach lub urządzeniach z ograniczonymi zasobami.
- Prowadzić do większego marnowania zasobów, jeśli użytkownik nie przejdzie do strony.
Aby prawidłowo skonfigurować renderowanie wstępne, należy wziąć pod uwagę zachowanie użytkowników i przeanalizować typowe nawigacje w witrynie. Korzystając z map cieplnych i schematów blokowych Google Analytics, możesz zidentyfikować najważniejsze trasy i rozpocząć eksperymenty z predykcyjnym ładowaniem.
Aby sprawdzić, czy strona jest wstępnie renderowana, użyj niezerowego wpisu aktywacyjnego Start parametru PerformanceNavigationTiming . Można to następnie zarejestrować przy użyciu wymiaru niestandardowego:

W ten sposób będziesz mógł ocenić stosunek między renderowaniem wstępnym a innymi typami nawigacji.
Ponadto ważne jest mierzenie liczby wstępnie renderowanych stron, które nie są następnie odwiedzane, aby zoptymalizować zasady spekulacji i osiągnąć wyższy współczynnik trafień i mniejsze marnowanie zasobów.
Można to zrobić, uruchamiając zdarzenie analityczne po wstawieniu reguł spekulacji, aby wskazać, że zażądano wstępnego renderowania. Następnie porównaj liczbę tych zdarzeń z rzeczywistą liczbą wyświetleń strony przed renderowaniem.
Możesz też…
Rozważ automatyczne wstępne renderowanie strony za pomocą sztucznej inteligencji nawigacji firmy NitroPack
Nawigacja AI to oparty na sztucznej inteligencji optymalizator przeglądania sieci NitroPack, który aktywnie przewiduje i analizuje zachowania użytkowników, aby wstępnie renderować całe strony podczas podróży klienta.
Nawigacyjna sztuczna inteligencja umożliwia właścicielom witryn oferowanie natychmiastowego przeglądania na komputerach stacjonarnych i urządzeniach mobilnychbez pisania ani jednej linii kodu , zwiększając zaangażowanie klientów i współczynniki konwersji.
Uwaga: AI nawigacji to osobny produkt, ale jest w 100% kompatybilny z NitroPack i dodatkowo zwiększa korzyści dla właścicieli witryn.
Dołącz do listy oczekujących na Nawigację AI i odblokuj natychmiastowe doświadczenia użytkowników w swojej witrynie →
Nawigacyjna sztuczna inteligencja firmy NitroPack opiera się na interfejsie API reguł spekulacji i oferuje zautomatyzowane rozwiązanie umożliwiające uzyskanie wysokiego współczynnika trafień i efektywnego wykorzystania zasobów w scenariuszach wstępnego renderowania.

Stosując ulepszone przez sztuczną inteligencję wstępne przewidywania dotyczące ładowania strony na podstawie danych i analizując zachowanie użytkowników, nawigacyjna sztuczna inteligencja może dostosować przewidywania i dokładnie poinstruować interfejs API reguł spekulacji, aby wstępnie renderował strony, które faktycznie będą odwiedzane.
Rezultatem jest natychmiastowe ładowanie strony dzięki temu, że strona jest już pomalowana w tle. Na urządzeniach mobilnych nawigacja AI opiera się na identyfikowaniu miejsca, w którym użytkownik znajduje się na stronie, a biorąc pod uwagę mały obszar wyświetlania, może łatwo przewidzieć, gdzie użytkownik kliknie.
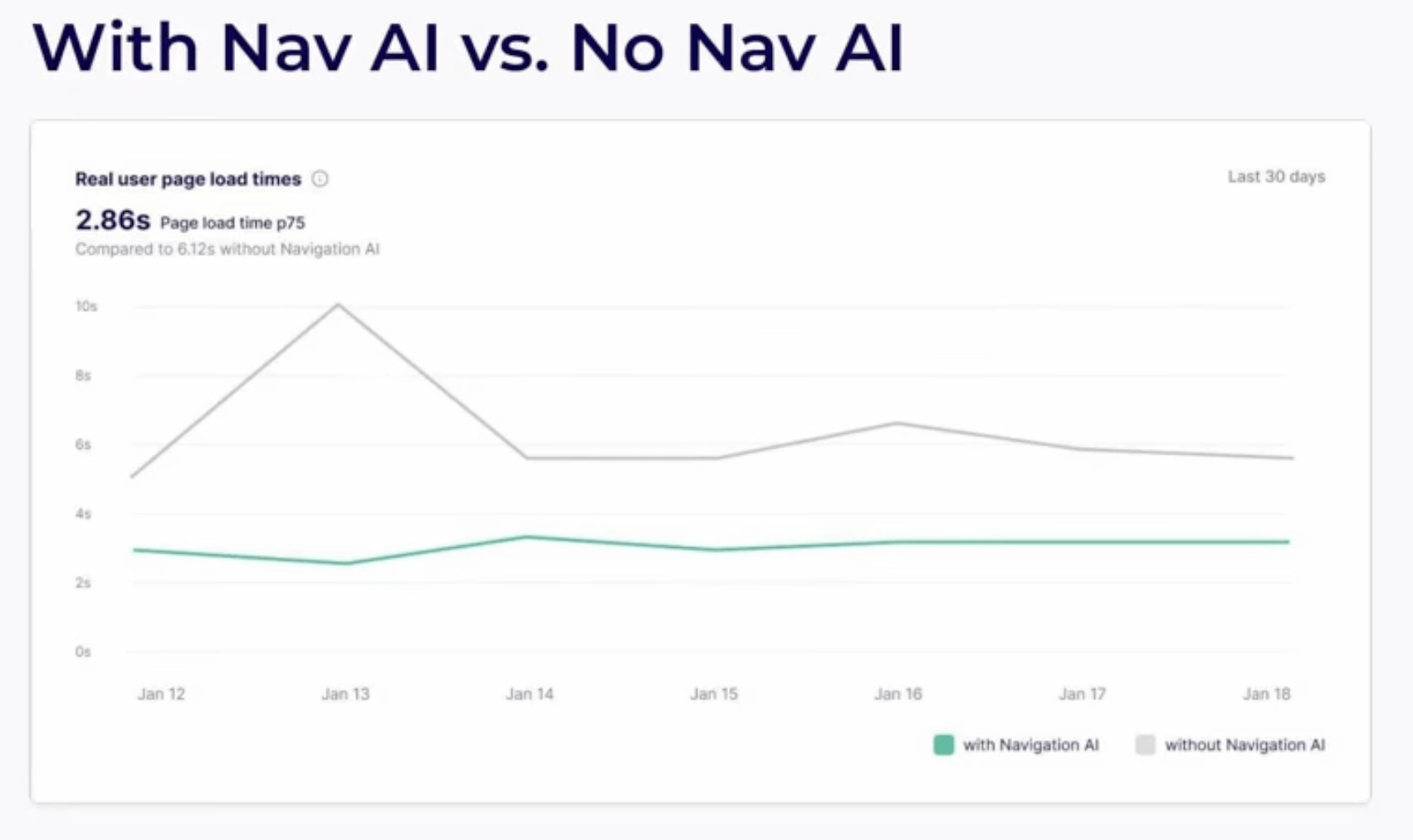
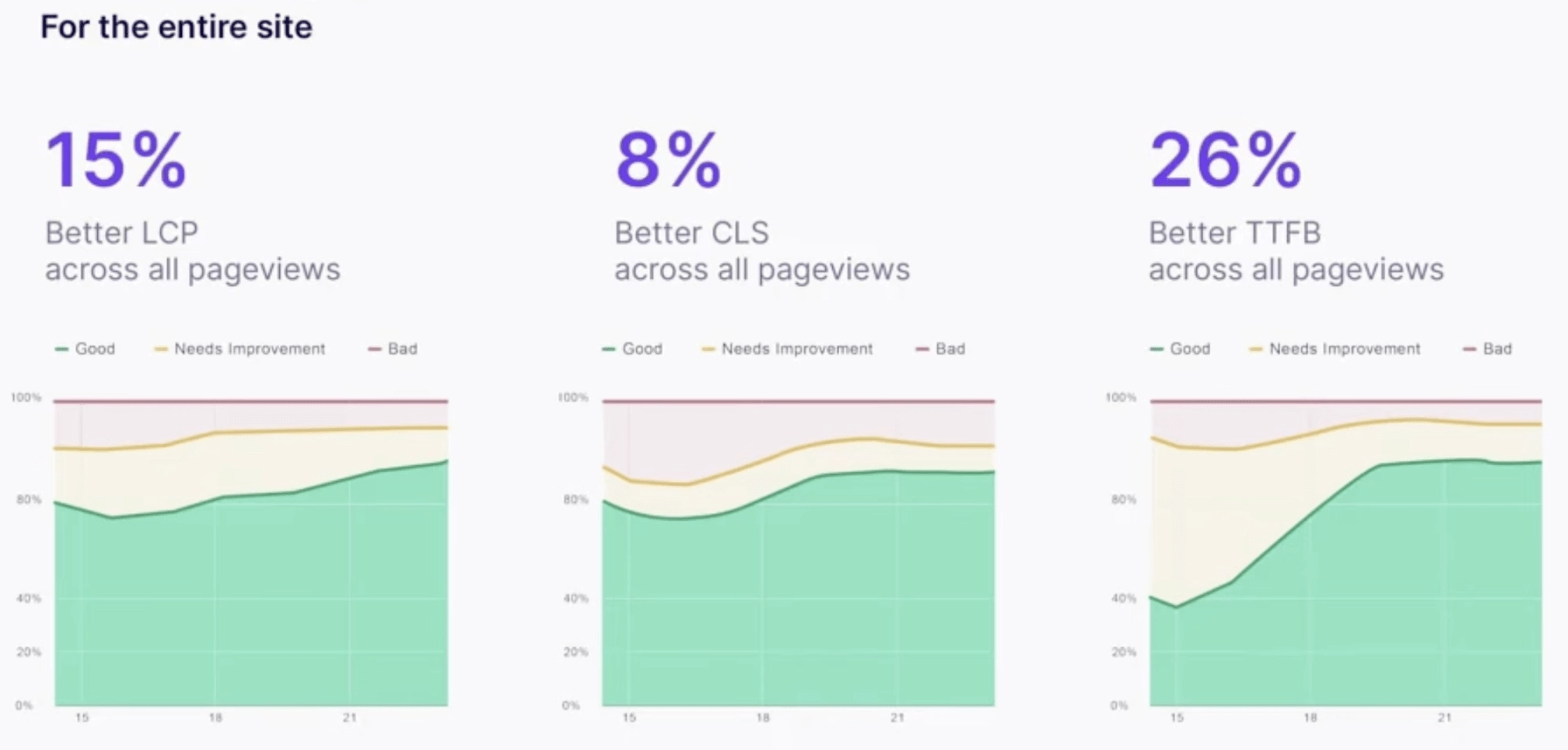
Bazując na 1200 stronach internetowych, Nawigacja AI już teraz wykazuje spektakularne rezultaty.
- Wynik nr 1: Strony internetowe wykorzystujące nawigacyjną sztuczną inteligencję stale pokazują czas ładowania ~2,86 s w porównaniu do 6,12 s bez nawigacji AI
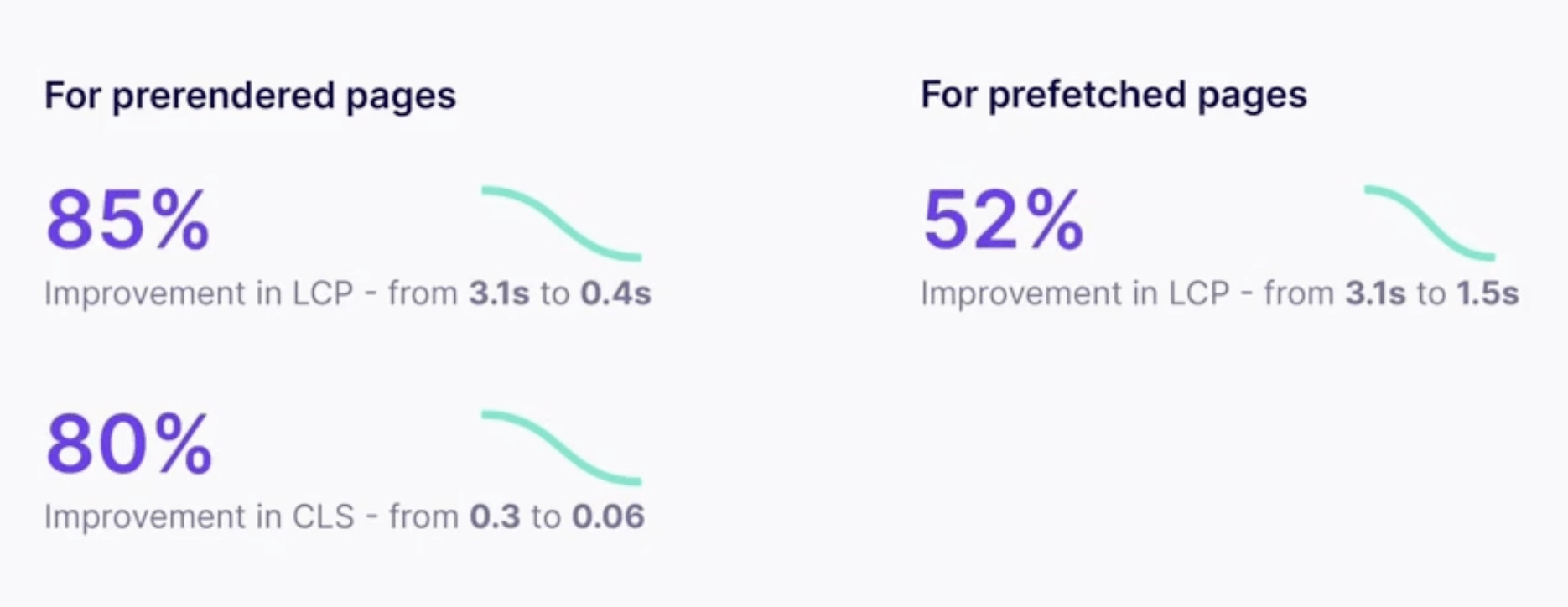
- Wynik nr 2: Dzięki nawigacji AI wstępnie renderowane strony wykazują poprawę LCP o 85% (z 3,1 s do 0,4 s) i poprawę CLS o 80% (z 0,3 s do 0,06 s).W przypadku stron pobieranych z wyprzedzeniem sztuczna inteligencja nawigacji zwiększa LCP o 52% (z 3,1 s do 1,5 s).
- Wynik nr 3: Dzięki nawigacji AI wskaźniki wydajności całej witryny znacznie się poprawiają: LCP o 15%, CLS o 8% i TTFB o 26%
Uzyskaj dostęp do AI nawigacji, dołączając do naszej listy oczekujących →
API reguł spekulacji i WordPress
Podczas naszego seminarium internetowego „Natychmiastowe ładowanie strony” inżynier Google ds. relacji z programistami, Adam Silverstein, ujawnił, że zespół WordPress Core Performance pracuje nad stabilniejszymi implementacjami nowego interfejsu API reguł spekulacji.
Obecnie koncentrujemy się na udostępnieniu niewielkiej części funkcjonalności interfejsu API właścicielom witryn i programistom w ekosystemie w celu przetestowania wydajności i tempa wdrażania, zanim stanie się on częścią rdzenia. Oto, co użytkownicy WordPressa mogą dotychczas wykorzystać:
- Moduł we wtyczce Performance Lab
- Samodzielna wtyczka, która implementuje wyłącznie interfejs API reguł spekulacji (stosuje konserwatywny poziom „zapału”, ale programiści mogą dowolnie modyfikować zachowanie)
Trasy administratora WP są domyślnie wykluczone, ale od programistów WP zależy, które trasy będą dla nich priorytetem.
Zespół WordPress Core Performance pracuje także nad bardziej wyrafinowanymi wdrożeniami w ramach wtyczek w ekosystemie. Ma to na celu odciążenie niektórych deweloperów od ciężkiej pracy przy ustalaniu, które trasy są najważniejsze, a które nie.
Jakie ulepszenia zostaną wprowadzone w zasadach spekulacji
Obecnie zasady spekulacji ograniczają się do stron znajdujących się w tej samej zakładce, jednak trwają prace nad zmniejszeniem tych ograniczeń.
Wstępne renderowanie jest domyślnie ograniczone do stron tego samego źródła. Jednak niedawna aktualizacja przeglądarki Chrome 119 obsługuje teraz wstępne renderowanie stron pochodzących z tej samej witryny, co wymaga zgody poprzez nagłówek HTTP.
Przyszłe wersje mogą rozszerzyć wstępne renderowanie na strony z różnych źródeł i umożliwić to w nowych kartach. Interfejs API reguł spekulacji zostanie rozszerzony, wprowadzając oceny i składnię reguł dokumentów oraz zapewniając większą elastyczność, np. wstępne renderowanie łączy po naciśnięciu przycisku myszy.
Trwające eksperymenty w przeglądarce Chrome badają dodatkowe funkcje, a witryny mogą wziąć udział w wersji próbnej Origin, aby przetestować i przekazać opinię na temat potencjalnych przyszłych dodatków.