
新しい Google データセット検索エンジンの完全ガイド – Promptcloud
公開: 2018-10-18最初の機械学習アルゴリズムを作成したとき、私はUC Irvine がホストする巨大なデータ セット コレクションを使用して、ロープを学習しました。 練習するデータセットは非常に多く、正確には 442 でした。 しかし問題は、これらが世界中の多くの人々によって使用されてきたデータセットであり、そこから得られるほとんどすべての調査結果がすでに公開されていることです. また、データサイエンスは多くの分野で進歩しています。 調査したいデータセットの種類は無限にあります。 その場合、442 は非常に小さく、大海の一滴に近いものであり、Google データセット検索も存在します。
しかし、何かを検索する必要があるときはいつでも、それを「Google」で検索しますよね? したがって、ある地域のがん患者の詳細を含むデータ セットが必要な場合、都市部に住むと致命的な病気にかかる可能性が高くなるかどうかを調べるには、おそらくそれを「グーグル検索」することになります。 ただし、理解する必要があるのは、Google は単語の一致に基づいて機能するということです。 検索すると、実際のデータセットを提供するよりも、「がん患者のデータセット」という単語を含む記事を取得する可能性が高くなります。 これが、Google が今年の 9 月 5 日に Google データセット検索のベータ版を開始した理由です。
これで、キーワードを検索して、それらに関連付けられたデータセットを見つけることができます。 しかし、何を検索する必要がありますか? Google で検索する際に役立つ特定のトリックやヒントは、誰もが知っています。 特定の Google を検索するときに、そのような規則は適用されますか? 確かに、Google によると、データセットの名前、説明、作成者情報、形式 (CSV、JSON など) などの情報を提供すると、Google 検索エンジンからデータセットを収集する方がはるかに簡単であることがわかります。 )。 マークアップ言語のデータセットでさえ、まったく新しい検索エンジンの助けを借りて発見できます。
Google にウェブサイト内のデータセットを見つけてユーザーに表示してもらいたい人のために、Google によると、この機能はパイロット段階にありますが、順調に進んでおり、ウェブサイトに構造化データを追加することでデータセットの追加を開始できます。人々が関連する用語で検索すると、最終的に検索エンジンに表示されます。
なぜGoogleは今これを構築したのですか?
Web 上にはデータを含む何千ものリポジトリがあり、何百万ものデータセットへのアクセスを提供しています。 これらのデータセットは、国、国際、または地域の政府、非営利組織、さらにはデータセットの取り扱いに一般市民を巻き込みたい企業に属している場合があります。 膨大な量のデータセットが研究機関や高等教育機関によって公開されています。 これらすべてのデータセットへのアクセスは、情報の流れを容易にするために重要です。 1,000 ドルの料金で閉じ込められたデータセットは、データから何らかの意味を理解できたはずの多くの研究者の手の届かないところにある可能性があります。
しかし、問題はボリュームにあります。 インターネット上には非常に多くのデータがあるため、たとえカテゴリ、サブカテゴリ、地域などに絞り込むことができたとしても、特定のデータセットを見つけることは非常に難しいことがわかっています. 病気、映画、植物、動物、災害、UFO 目撃情報などに関するデータを探しているかどうかを指定できます。 理論的に言えば、これらは簡単に見つけることができるはずです。 しかし、現在はそうではありません。
Google は、Google がデータセットをより簡単に追跡できるように、いくつかの標準によって管理される特定の形式でメタデータを添付できるようにすることで、問題を解決しています。 これらのメタデータは、Google がデータセットを一般に簡単にアクセスできるようにするのに役立ちます。

なぜプログラムがまだベータ版なのですか?
技術的な問題のほとんどは対処されていますが、主な課題はいくつかの未解決の問題です。 これらの質問のいくつかは次のとおりです – データセットの普遍的な定義は何ですか? 1 つのテーブルをデータセットと呼ぶことはできますか? テーブルのコレクションはどうですか? 画像フォルダ? フォルダ内の画像に関連性があるとどのように言えますか? または、一緒に見つかったテーブルは関連していますか? データセットを提供する API はどうですか? 特定のパラメーターを使用して類似のデータセットを関連付けることは可能ですか?
問題は、データセットが長い時間をかけて構築され、さまざまな形式で保存されていることです。また、インターネットの奥深くからすぐに識別できる一次データやメタデータ、またはタグを見つける方法がありません。これが Google が取り組もうとしているものです。 したがって、彼らが推奨しているのは、データをアップロードする人は適切な規則に従い、研究でデータを使用する人は適切な引用を提供することです. 結局のところ、Google は単なる検索エンジンです。 これは、既存のデータを示しています。 見つからない状態にあるものを見つけることはできません。 推奨される形式で保存し、メタデータや引用を追加することによって、人々が責任を持ってデータを処理し始めない限り、毎日ますます多くのデータセットが Web に追加されるにつれて、事態は悪化するだけです。
さて、Google データセット検索の使い方は?
さまざまなタイプのデータセットを検索できます。 Google によると、データセットは次のいずれかになります。
- 相互に関連するテーブルの集まり
- CSV またはテーブル形式のデータ
- 一連の画像または動画
- データを含む独自の形式のファイル
- 何らかの形式のデータセットを一緒に構成するファイルのコレクション
- データセットを構築するために処理できる、JSON のようなオブジェクト。
- Tensorflow によって生成されるようなバイナリ モデル
- 肉眼ではデータセットのようにさえ見えるものすべて。
検索エンジンは次のようになります。通常の Google ウェブ検索と同じように検索できます。
 そこで、住宅データセットを検索したところ、次の結果が得られました。
そこで、住宅データセットを検索したところ、次の結果が得られました。
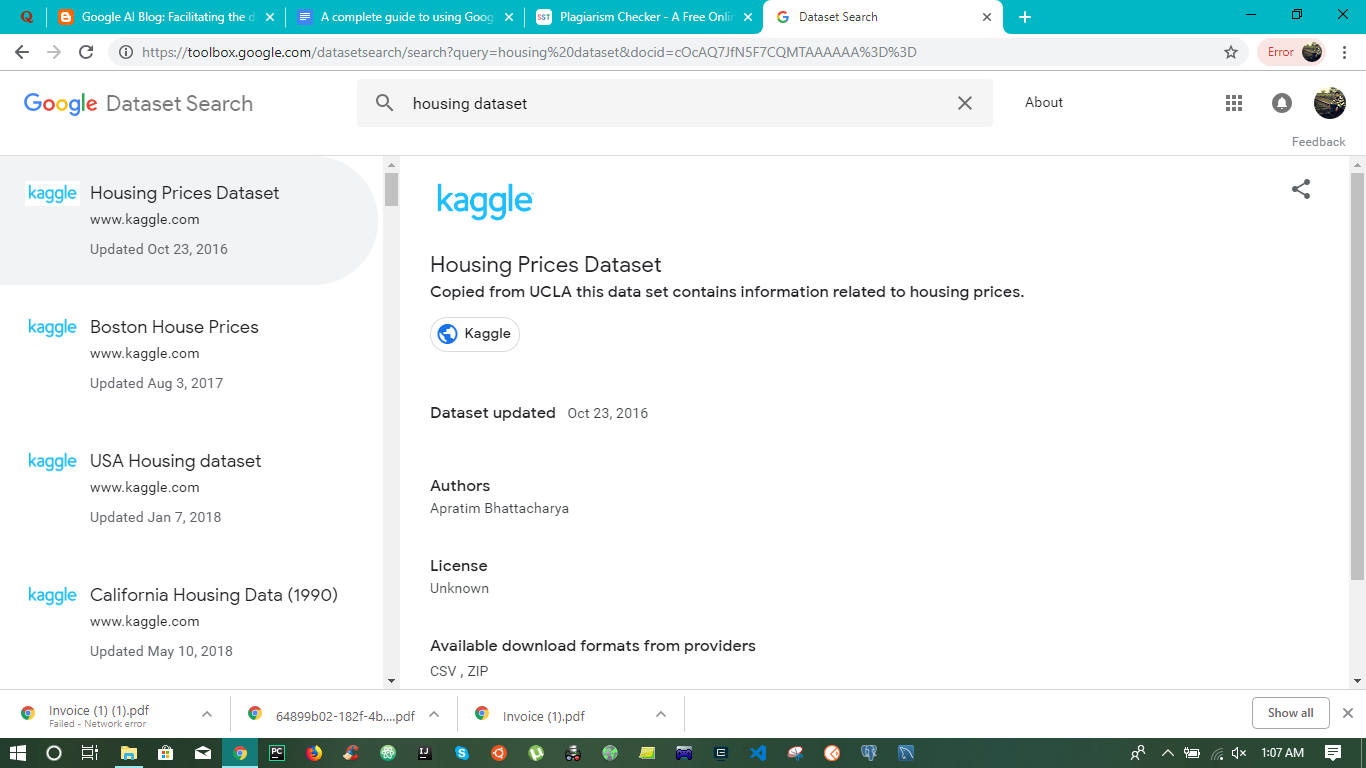
Google は、私が入力した 2 つの単語だけに関連する、最も関連性が高く人気のあるデータセットを表示しようとしていることがわかります。このシナリオでは、Kaggle には、何千人ものユーザーが使用した住宅データセットが多数あります。上。
次に、もう少し具体的なものを探しました。 そして、次の結果を得ました:

今回は、特定の何かを検索したため、Google がそのリソースを特定できたことがわかります。これにより、作業をより迅速にスケールアップすることができました。 また、Google は、使用したいデータセットについて理解を深めるための基本的な説明とリンクも提供しています。
このようなサービスは天の恵みであり、私がデータ サイエンスを学び始めたときにこれが利用できればよかったのにと思います。 Google でデータセットを検索し、検索しようとしているデータセットについてできるだけ多くの情報を提供して、プロジェクト、研究、または研究に最適なデータセットを見つけることをお勧めします。 一方、必要なデータがすぐに使用できる形式でウェブ上にない場合は、いつでもご連絡いただければ、カスタム クロールを設定できます。
PromptCloud に連絡してデータを抽出するための Web スクレイピング サービスを探しています