
La voce del bazar
Pubblicato: 2024-04-24Questo articolo sulla modernizzazione dei sistemi legacy è complementare a un discorso che ho presentato di recente all'AWS Data Summit per le aziende di software sulla generazione di valore dai dati sfruttando le nostre migliori pratiche per garantire il successo nei progetti di machine learning. Puoi saltare fino in fondo qui per guardarlo se preferisci.
Diciamolo chiaro: il software è più facile da scrivere che da mantenere. Questo è il motivo per cui noi, come ingegneri del software, preferiamo semplicemente "strapparlo e ricominciare da capo" invece di cercare di capire cosa stava pensando un altro sviluppatore (o il nostro sé passato). Sembra che abbiamo dimenticato collettivamente che “i programmi devono essere scritti affinché le persone possano leggerli, e solo incidentalmente perché le macchine possano eseguirli”.
Sai che è vero: abbiamo tutti dovuto rintracciare scrupolosamente una casseruola di codici di spaghetti e sottili astrazioni vecchio stile scavando alla ricerca della carne del programma solo per trovare nient'altro che un disastro sul fondo dei nostri piatti.
È facile urlare "WTF" e incolpare lo sviluppatore precedente, ma la verità è spesso più complicata. Non possiamo vedere il futuro, quindi è impossibile capire come cresceranno i requisiti, la tecnologia o gli obiettivi aziendali quando progettiamo un sistema completamente nuovo. Di conseguenza, i sistemi possono diventare illeggibili man mano che la loro portata aumenta insieme alla dipendenza dell'azienda da essi. Questo è un po’ un paradosso: i sistemi più vecchi e più difficili da mantenere spesso forniscono il massimo valore. È difficile lavorarci perché sono cresciuti con l'azienda, ed è spaventoso lavorarci perché romperli potrebbe essere una catastrofe.
Ecco perché ti sto chiamando: se ti piacciono i problemi difficili e gratificanti... provaci. Prendi il sistema più vecchio che hai e rendilo manutenibile. Sai quello di cui sto parlando: quello che nessuno “possederà”. Quello da cui dipendono gli altri dipartimenti ma che gli ingegneri odiano. Quello su cui dovevi prima applicare la patch a Log4Shell. Fallo. Io ti sfido.
Recentemente ho avuto l'opportunità di aggiornare un sistema di apprendimento automatico vecchio di dieci anni su Bazaarvoice. In apparenza la cosa non sembrava entusiasmante : questa cosa non aveva nemmeno reti neurali! Che importa! Beh... importava. Questo sistema elabora quasi tutte le recensioni di prodotti generate dagli utenti ricevute da Bazaarvoice – quasi 9 milioni al mese – e lo fa con 90 milioni di chiamate di inferenza a modelli di apprendimento automatico. Sì, 90 milioni di inferenze! È una scala enorme e non vedevo l'ora di tuffarmi.
In questo post condividerò come la modernizzazione di questo sistema legacy attraverso una riarchitettura, invece che una riscrittura, ci ha permesso di renderlo scalabile ed economico senza dover eliminare tutto il codice e ricominciare da capo. Il sistema risultante è serverless, containerizzato e manutenibile, riducendo al tempo stesso i costi di hosting di quasi l'80%.
Cos'è un sistema legacy?
Un sistema legacy si riferisce a software e/o hardware informatici obsoleti che rimangono in funzione. Sebbene possa ancora soddisfare il suo scopo originale, manca di scalabilità per la crescita futura.
Vecchi sistemi legacy
Per prima cosa, diamo un'occhiata a ciò con cui abbiamo a che fare qui. Il sistema legacy che il mio team stava aggiornando modera i contenuti generati dagli utenti per tutto Bazaarvoice. Nello specifico, determina se ciascun contenuto è appropriato per i siti web dei nostri clienti.

Sembra semplice – eliminare infrazioni evidenti come incitamento all'odio, linguaggio volgare o sollecitazioni – ma in pratica è molto più sfumato. Ogni cliente ha requisiti unici per ciò che ritiene appropriato. I marchi di birra, ad esempio, si aspetterebbero discussioni sull'alcol, ma un marchio per bambini no. Catturiamo queste opzioni specifiche del cliente quando ne acquisiamo di nuovi e il nostro team del Servizio clienti le codifica in un database di gestione.
Per una maggiore complessità, campioniamo anche un sottoinsieme dei nostri contenuti per essere moderati da moderatori umani. Ciò ci consente di misurare continuamente le prestazioni dei nostri modelli e scoprire opportunità per costruire più modelli.
L'architettura completa del nostro sistema legacy è mostrata di seguito:
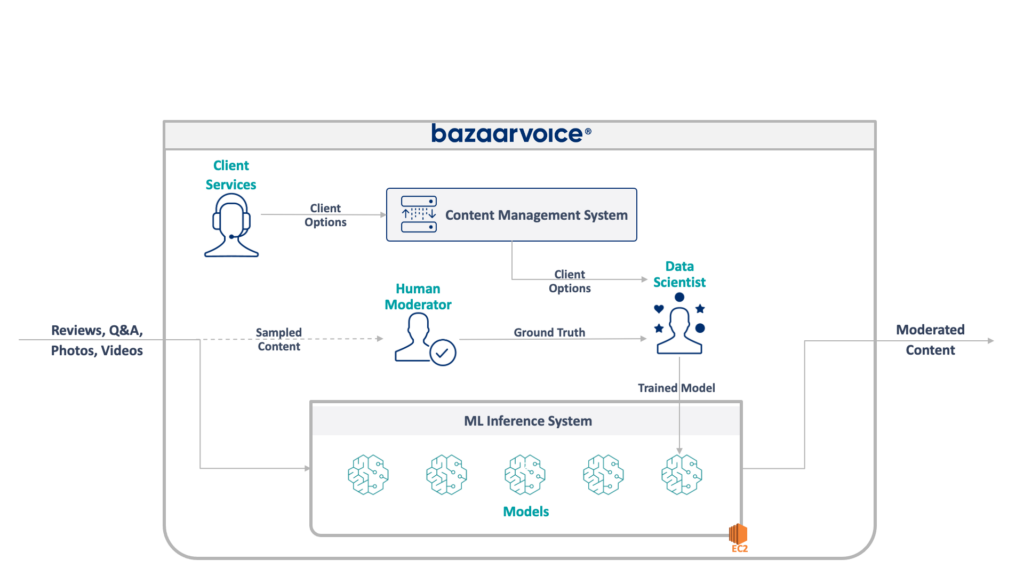
Questo sistema presenta alcuni gravi inconvenienti. Nello specifico: tutti i modelli sono ospitati su una singola istanza EC2. Ciò non era dovuto a una cattiva progettazione, ma semplicemente all'incapacità dei programmatori originali di prevedere la scala desiderata dall'azienda. Nessuno pensava che sarebbe cresciuto così tanto.
Inoltre, il sistema soffriva del rifiuto degli sviluppatori: era scritto in Scala, cosa che pochi ingegneri capivano. Pertanto, veniva spesso trascurato per eventuali miglioramenti poiché nessuno voleva toccarlo.
Di conseguenza, il sistema ha continuato a crescere mantenendo le luci accese. Una volta che siamo riusciti a riprogettarlo, funzionava su una singola istanza x1e.8xlarge. Questa cosa aveva quasi un terabyte di RAM e costava circa $ 5.000 al mese (senza riserve) per funzionare. Non preoccuparti, però, ne abbiamo appena lanciato un secondo per la ridondanza e un terzo per il QA.
Questo sistema era costoso da gestire e presentava un alto rischio di fallimento (un singolo modello difettoso può interrompere l'intero servizio). Inoltre, il codice base non era stato sviluppato attivamente ed era quindi notevolmente obsoleto rispetto ai moderni pacchetti di data science e non seguiva le nostre pratiche standard per i servizi scritti in Scala.
Un nuovo sistema
Nel riprogettare questo sistema avevamo un obiettivo chiaro: renderlo scalabile. La riduzione dei costi operativi era un obiettivo secondario, così come la semplificazione della gestione di modelli e codici.
Il nuovo design che abbiamo ideato è illustrato di seguito:
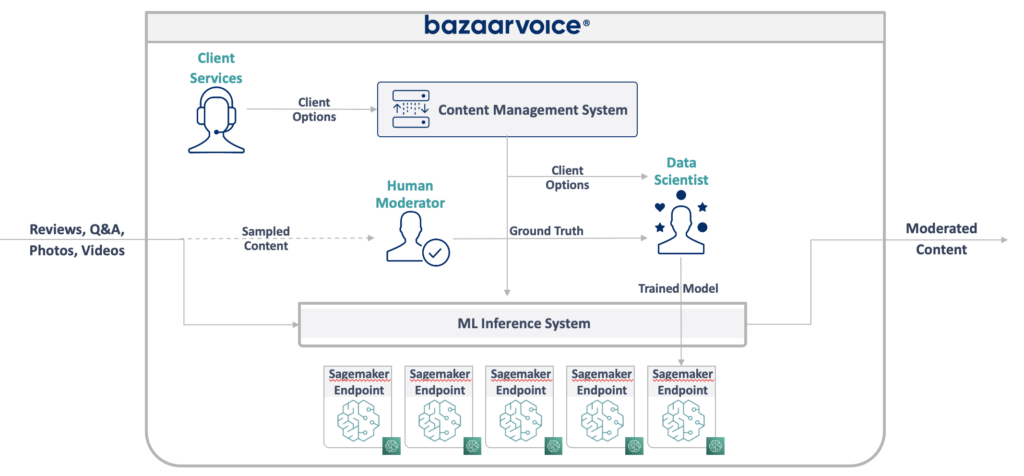
Il nostro approccio per risolvere tutto questo è stato quello di inserire ciascun modello di machine learning su un endpoint SageMaker Serverless isolato. Come le funzioni AWS Lambda, gli endpoint serverless si spengono quando non vengono utilizzati, risparmiandoci sui costi di runtime per i modelli utilizzati di rado. Possono anche espandersi rapidamente in risposta all'aumento del traffico.

Inoltre, abbiamo esposto le opzioni client a un singolo microservizio che instrada i contenuti ai modelli appropriati. Questa era la maggior parte del nuovo codice che dovevamo scrivere: una piccola API facile da mantenere e che consentiva ai nostri data scientist di aggiornare e distribuire più facilmente nuovi modelli.
Questo approccio presenta i seguenti vantaggi:
- Diminuito il time-to-value di oltre 6 volte. Nello specifico, l'instradamento del traffico verso i modelli esistenti è istantaneo e la distribuzione di nuovi modelli può essere eseguita in meno di 5 minuti anziché 30
- Scalabilità senza limiti: attualmente disponiamo di 400 modelli, ma prevediamo di arrivare a migliaia per continuare ad aumentare la quantità di contenuti che possiamo moderare automaticamente
- Abbiamo riscontrato una riduzione dei costi dell'82% abbandonando EC2 poiché le funzioni si disattivano quando non vengono utilizzate e non stiamo pagando per macchine di livello superiore sottoutilizzate
Progettare semplicemente un'architettura ideale, tuttavia, non è la parte più difficile e interessante della ricostruzione di un sistema legacy: è necessario migrare ad esso.
La nostra prima sfida nella migrazione è stata capire come diavolo migrare un modello Java WEKA da eseguire su SageMaker, per non parlare di SageMaker Serverless.
Fortunatamente, SageMaker distribuisce modelli in contenitori Docker, quindi almeno potremmo bloccare le versioni Java e delle dipendenze in modo che corrispondano al nostro vecchio codice. Ciò contribuirebbe a garantire che i modelli ospitati nel nuovo sistema restituiscano gli stessi risultati di quello precedente.

Per rendere il contenitore compatibile con SageMaker, tutto ciò che devi fare è implementare alcuni endpoint HTTP specifici:
-
POST /invocation: accetta input, esegue inferenza e restituisce risultati. -
GET /ping: restituisce 200 se il server JVM è integro
(Abbiamo scelto di ignorare tutte le complicazioni relative ai contenitori multimodello BYO e al toolkit di inferenza SageMaker.)
Alcune rapide astrazioni su com.sun.net.httpserver.HttpServer ed eravamo pronti a partire.
E tu sai cosa? In realtà è stato piuttosto divertente. Giocare con i contenitori Docker e forzare qualcosa di vecchio di 10 anni in SageMaker Serverless aveva un'atmosfera un po' da armeggiare. È stato piuttosto emozionante quando l'abbiamo fatto funzionare, soprattutto quando abbiamo ottenuto il codice del sistema legacy per costruirlo nel nostro nuovo stack sbt invece che in maven.
Il nuovo stack sbt ha semplificato il lavoro e la containerizzazione ha assicurato che potessimo ottenere un comportamento corretto durante l'esecuzione nell'ambiente SageMaker.
Migrazione a un nuovo sistema
Quindi abbiamo i modelli in contenitori e possiamo distribuirli su SageMaker: quasi finito, giusto? Non proprio.
La dura lezione sulla migrazione a una nuova architettura è che è necessario costruire tre volte il sistema attuale solo per supportare la migrazione. Oltre al nuovo sistema, abbiamo dovuto realizzare:
- Una pipeline di acquisizione dati nel vecchio sistema per registrare input e output dal modello. Li abbiamo usati per confermare che il nuovo sistema avrebbe restituito gli stessi risultati
- Una pipeline di elaborazione dati nel nuovo sistema per calcolare i risultati e confrontarli con i dati del vecchio sistema. Ciò comportava una grande quantità di misurazioni con Datadog ed era necessario offrire la possibilità di riprodurre i dati quando rilevavamo discrepanze
- Un sistema di distribuzione del modello completo per evitare impatti sugli utenti del vecchio sistema (che avrebbero semplicemente caricato i modelli su S3). Sapevamo che prima o poi avremmo voluto spostarli su un'API, ma per la versione iniziale dovevamo farlo senza problemi
Tutto questo era codice usa e getta che sapevamo di poter eliminare una volta terminata la migrazione di tutti gli utenti, ma dovevamo ancora crearlo e garantire che gli output del nuovo sistema corrispondessero al vecchio.
Aspettatevi questo in anticipo.
Sebbene la creazione degli strumenti e dei sistemi di migrazione abbia sicuramente richiesto più del 60% del nostro tempo di progettazione su questo progetto, è stata anche un'esperienza divertente. I test unitari sono diventati più simili a esperimenti di data science: abbiamo scritto intere suite per garantire che il nostro output corrispondesse esattamente . Era un modo diverso di pensare che rendeva il lavoro ancora più divertente. Un passo fuori dai nostri schemi normali, se vuoi.
Modernizzare i sistemi legacy attraverso una riarchitettura
La prossima volta che sarai tentato di ricostruire un sistema dal codice, vorrei incoraggiarti a provare a migrare l'architettura invece del codice. Troverai sfide tecniche interessanti e gratificanti e probabilmente ti divertirai molto di più che eseguire il debug di casi limite imprevisti del tuo nuovo codice.
Vuoi saperne di più? Guarda il discorso che ho tenuto all'AWS Data Summit, di seguito, che approfondisce il lato MLOps delle cose.