
Qu'est-ce que l'étiquetage des données dans l'apprentissage automatique et comment fonctionne-t-il ?
Publié: 2022-04-29Les données sont la nouvelle richesse des entreprises d'aujourd'hui. Avec des technologies telles que l'intelligence artificielle qui prennent progressivement le contrôle de la plupart de nos activités quotidiennes, le bon usage de toutes les données a influencé positivement la société. En séparant et en étiquetant efficacement les données, les algorithmes ML peuvent découvrir les problèmes et fournir des solutions pratiques et pertinentes.
À l'aide de l'étiquetage des données, nous enseignons à la machine différentes techniques et saisissons les informations dans différents formats pour qu'elles se comportent « intelligemment ». La science derrière l'étiquetage des données implique beaucoup de devoirs sous la forme d'annotations ou d'étiquetage des ensembles de données avec de multiples variations de la même information. Bien que le résultat final surprenne et facilite notre vie quotidienne, le travail derrière est immense et le dévouement louable.
Qu'est-ce que l'étiquetage des données ?
Dans l'apprentissage automatique, la qualité et le type de données d'entrée déterminent la qualité et le type de sortie. La qualité des données utilisées pour former la machine augmente la précision de votre modèle d'IA.
En d'autres termes, l'étiquetage des données est un processus permettant d'entraîner une machine à trouver les différences et les similitudes entre les ensembles de données non structurées ou structurées en les étiquetant ou en les annotant.

Comprenons cela avec un exemple. Pour apprendre à la machine que le feu rouge est le signe d'arrêt, vous devez étiqueter tous les feux rouges sur différentes images pour que la machine comprenne le signal. Sur cette base, l'IA crée un algorithme qui lit le feu rouge comme un signal d'arrêt dans chaque scénario donné. Un autre exemple est que les genres musicaux peuvent être séparés avec plusieurs ensembles de données sous les étiquettes jazz, pop, rock, classique, etc.
Les défis de l'étiquetage des données
Tout nouveau changement/progrès dans la technologie ou la structure apporte ses avantages et ses défis. Ce n'est pas différent pour l'étiquetage des données. Bien que l'étiquetage des données puisse réduire considérablement le temps de mise à l' échelle d'une entreprise , il a un coût. Arrêtons-nous sur certains des défis que pose l'étiquetage des données.
Coût en termes de temps et d'effort
C'est une tâche difficile en soi d'obtenir les données spécifiques à une niche en grandes quantités. L'ajout manuel de balises pour chaque élément ne fait qu'ajouter à la tâche déjà fastidieuse. Si le projet est géré en interne, la majeure partie du temps du projet est consacrée à des tâches liées aux données telles que la collecte, la préparation et l'étiquetage des données.
Pour gérer ces tâches efficacement, afin que vous fassiez le travail correctement du premier coup, vous aurez besoin d'étiqueteuses expertes possédant cette expertise spécifique. C'est aussi une entreprise coûteuse, ce qui la rend coûteuse, non seulement en termes de temps mais aussi d'argent.
Incohérence
Des annotateurs ayant une expertise différente peuvent avoir des critères d'étiquetage différents. Par conséquent, il existe une forte possibilité d'étiquetage incohérent. Cela dit, lorsque plusieurs personnes étiquettent le même ensemble de données, les taux de précision des données seront beaucoup plus élevés.
Domaine d'expertise
Pour des industries spécifiques, vous ressentirez le besoin d'embaucher des étiqueteurs ayant une expertise dans un domaine spécifique. Par exemple, pour créer une application ML pour le secteur de la santé , les annotateurs sans expertise pertinente dans le domaine trouveront très difficile de baliser correctement les éléments.
Imperfections
Tout travail répétitif effectué par des humains est sujet à des erreurs. Quel que soit le niveau d'expertise de l'étiqueteur humain, le marquage manuel aura toujours une portée d'imperfection. Il est pratiquement impossible de garantir l'absence d'erreurs, car les annotateurs doivent traiter de grands ensembles de données brutes pour l'étiquetage.
Approches de l'étiquetage des données
Comme mentionné ci-dessus, l'étiquetage des données est une tâche chronophage qui nécessite un souci du détail. En fonction de l'énoncé du problème, de la quantité de données à étiqueter, de la complexité des données et du style, la stratégie appliquée pour annoter les données variera.
Passons en revue différentes approches que votre entreprise peut opter en fonction des ressources financières et du temps disponible.
Étiquetage des données en interne
En fonction du type d'industrie, du temps disponible pour terminer le projet d'IA donné et de la disponibilité des ressources requises, le processus d'étiquetage des données peut être effectué en interne par les organisations.
Avantages:
- Haute précision
- Haute qualité
- Suivi simplifié
Les inconvénients:
- Prend du temps/lent
- Nécessite des ressources importantes
Crowdsourcing
Les ensembles de données de sourcing étiquetés par des indépendants sont disponibles sur diverses plateformes de crowdsourcing. Cette méthode peut être utilisée pour annoter des données généralisées comme des images.
L'exemple le plus célèbre d'étiquetage de données via le crowdsourcing est Recaptcha. L'utilisateur est invité à identifier des types d'images spécifiques pour prouver qu'il s'agit d'humains. Ceux-ci sont vérifiés sur la base des entrées données par d'autres utilisateurs. Cela agit comme une base de données d'étiquettes pour un tableau d'images.
Avantages:
- Rapide et facile
- Rentable
Les inconvénients:
- Ne peut pas être utilisé pour les données qui nécessitent une expertise du domaine
- La qualité n'est pas garantie
Externalisation
L'externalisation peut agir comme un intermédiaire entre l'étiquetage des données en interne et le crowdsourcing. L'embauche d'organisations tierces ou de personnes ayant une expertise dans le domaine peut aider les organisations dans tous leurs projets - à long terme et à court terme.
Avantages:
- Optimal pour les projets temporaires de haut niveau
- Les sociétés d'externalisation tierces fournissent du personnel contrôlé
- Fournit des outils d'étiquetage de données prédéfinis et personnalisés selon les besoins de votre entreprise
- Peut obtenir l'option d'experts en étiquetage de données spécifiques à un créneau
Les inconvénients:
- La gestion du tiers peut prendre du temps
Basé sur la machine
L'annotation automatique est l'une des dernières formes d'étiquetage et d'annotation des données largement utilisée et acceptée par les industries. L'automatisation du processus d'étiquetage des données à l'aide d'un logiciel d'étiquetage des données réduit l'intervention humaine et augmente la vitesse à laquelle l'étiquetage peut être effectué. Avec la technique appelée apprentissage actif, les données peuvent être étiquetées en fonction desquelles les balises peuvent être ajoutées automatiquement aux ensembles de données de formation.
Avantages:
- Traitement et étiquetage des données plus rapides
- Implique une moindre intervention humaine
Les inconvénients:
- Bien que de meilleure qualité mais pas à égalité avec le marquage humain
- En cas d'erreur, une intervention humaine est toujours nécessaire

Comment fonctionne l'étiquetage des données ?
En fonction des besoins de votre entreprise, vous pouvez choisir l'approche qui convient le mieux à vos besoins. Cependant, le processus d'étiquetage des données fonctionne dans l'ordre chronologique suivant.
Collecte de données
La base de tout projet d'apprentissage automatique, ce sont les données. La collecte de la bonne quantité de données brutes dans différents formats constitue la première étape de l'étiquetage des données. La collecte de données peut prendre deux formes - l'une que l'entreprise a collectée en interne et l'autre, qui est collectée à partir de sources externes accessibles au public.
Étant sous forme brute, ces données nécessitent un nettoyage et un traitement avant de créer les étiquettes pour les ensembles de données. Ces données nettoyées et prétraitées sont ensuite transmises au modèle pour la formation. Plus les données sont volumineuses et diversifiées, plus les résultats seront précis.
Annotation des données
Une fois les données nettoyées, les experts du domaine parcourent les données et ajoutent des étiquettes en suivant diverses approches d'étiquetage des données. Le contexte significatif est attaché au modèle qui peut être utilisé comme vérité terrain . Ce sont les variables cibles comme les images que vous voulez que le modèle prédise.

Assurance qualité
Le succès de la formation du modèle ML dépend fortement de la qualité des données qui doivent être fiables, précises et cohérentes. Pour garantir ces étiquettes de données précises et exactes, des contrôles d'assurance qualité réguliers doivent être mis en place. Avec l'utilisation d'algorithmes d'AQ comme le test alpha de Consensus et de Cronbach, l'exactitude de ces annotations peut être déterminée. Des contrôles d'assurance qualité réguliers contribuent grandement à l'exactitude des résultats.
Formation et test de modèles
L'exécution de toutes les étapes ci-dessus n'a de sens que si l'exactitude des données est testée. La saisie de l'ensemble de données non structuré pour voir s'il fournit les résultats attendus permettra de tester le processus.
Cas d'utilisation sectoriels pour l'étiquetage des données
Maintenant que nous savons ce qu'est l'étiquetage des données et comment il fonctionne, passons en revue les cas d'utilisation les plus importants.
Vision par ordinateur (CV)
Il s'agit d'un sous-ensemble d'IA qui permet aux machines de dériver une interprétation significative des entrées fournies sous forme de visuels et de vidéos (images fixes extraites pour le marquage).
L'annotation de vision par ordinateur peut être utilisée dans diverses industries pour mettre en œuvre les avantages pratiques de l'IA.
- Dans l'industrie automobile, l'étiquetage d'images et de vidéos pour segmenter les routes, les bâtiments, les piétons et d'autres objets aidera les véhicules autonomes à distinguer ces entités pour éviter tout contact dans la vie réelle.
- Dans l'industrie de la santé, les symptômes de la maladie peuvent être segmentés dans une radiographie, une IRM et une tomodensitométrie. À l'aide d'images microscopiques, la plupart des maladies critiques peuvent être diagnostiquées à un stade précoce.
- Les codes QR, les codes-barres d'étiquettes, etc. peuvent être utilisés comme étiquettes dans l'industrie du transport et de la logistique pour suivre les marchandises.
Traitement du langage naturel (TAL)
Il s'agit d'un sous-ensemble qui permet aux machines d'IA d'interpréter le langage humain et les statistiques. Dérivant le sens du texte et de la parole, l'algorithme peut analyser divers aspects linguistiques.
Le NLP est de plus en plus utilisé dans de nombreuses solutions d'entreprise .
- Il est couramment utilisé dans toutes les industries comme assistant de messagerie, fonction de saisie semi-automatique, correcteur orthographique, ségrégation des spams et des non-spams, et bien plus encore.
- Sous la forme de chatbots , les requêtes de base soulevées par les clients sont interprétées et répondues sans intervention humaine en temps réel. Il est prévu que 70 % des interactions avec les clients seront gérées par des chatbots et des applications de messagerie mobile d'ici 2023.
- Comprendre la polarité négative et positive du texte pour capturer le sentiment des clients se fait par l'étiquetage des données dans le commerce électronique.
Appinventiv a créé avec succès une application de médias sociaux pour Vyrb qui permet aux utilisateurs d'envoyer et de recevoir des messages audio optimisés pour les appareils portables Bluetooth.

Aperçu du marché de l'étiquetage des données de l'IA
L'étiquetage des données est une industrie florissante née de la technologie de l'IA . Comme l'étiquetage des données dépend en grande partie de l'exactitude des données fournies à l'apprentissage automatique, il est appelé à se développer au cours des prochaines années.
Le graphique ci-dessous montre clairement que l'industrie s'est développée et continuera de croître dans les années à venir. Il devrait connaître une croissance annuelle composée de 25,6 % et atteindre une taille de marché de 8,22 milliards USD d'ici 2028. Le graphique ci-dessous montre la croissance par type de données.
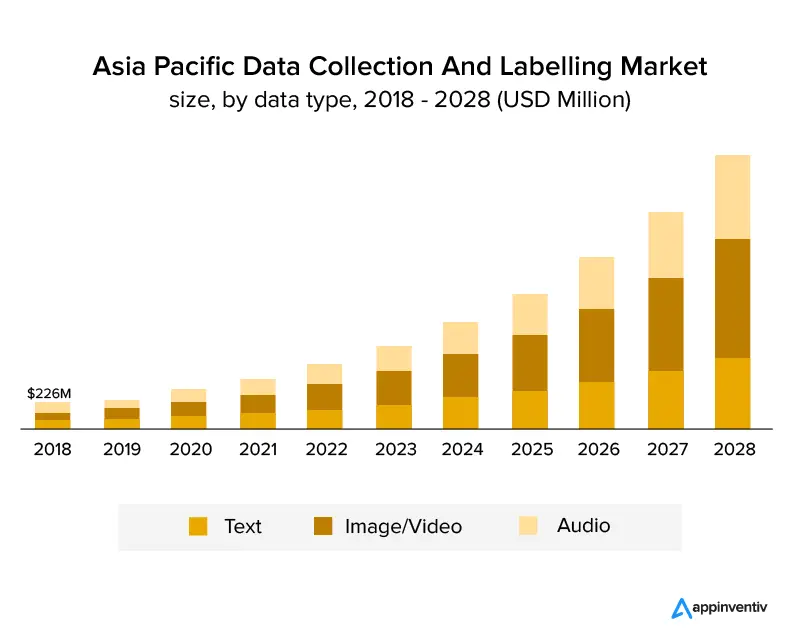
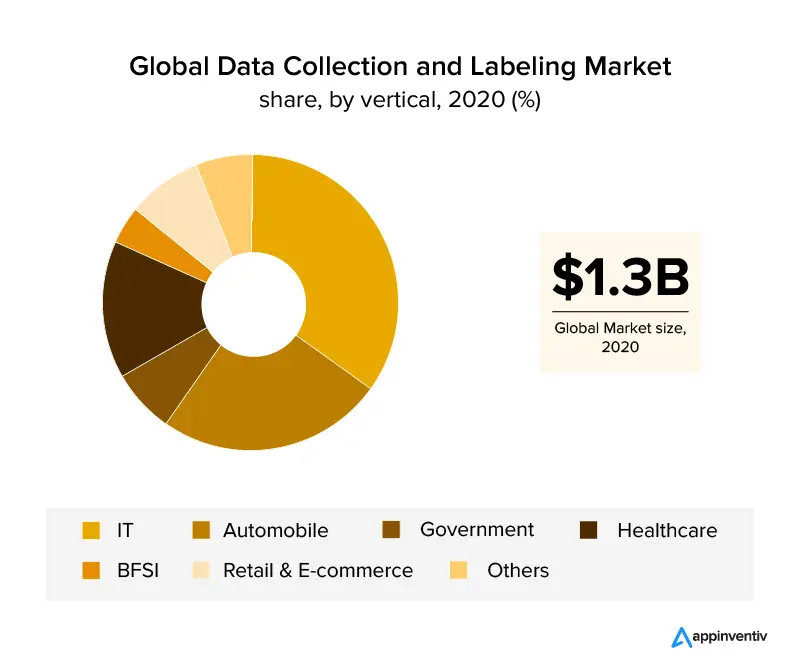
Les secteurs de l'informatique et de l'automobile, qui couvrent plus de 30 % du chiffre d'affaires mondial, constituent un aperçu des secteurs d'activité qui ont exploité l'étiquetage des données. Avec la croissance de l'industrie de la santé , on s'attend à ce que l'étiquetage des données explose en raison des exigences de données précises pour des applications efficaces basées sur l'IA dans le secteur. Avec l'aide de l'étiquetage d'image, les industries de la vente au détail et du commerce électronique ont également obtenu une part de marché importante dans l'industrie de l'étiquetage des données.
Labelliser les données avec Appinventiv
Stratégiquement, les entreprises ont externalisé les services de collecte de données et d'étiquetage pour créer de solides modèles d'apprentissage automatique.
Appinventiv est une société de développement d'IA et de ML qui aide les organisations à débloquer des opportunités avec des solutions basées sur l'IA depuis de nombreuses années maintenant . Avec près d'une décennie d'expérience dans la transformation d'entreprises, nous avons réalisé avec succès de nombreux projets d'IA complexes pour différentes industries.
Par exemple, Appinventiv a automatisé avec succès le processus bancaire d'une banque leader en Europe. Le processus d'automatisation a aidé la banque à améliorer la précision de 50 % et les niveaux de service des guichets automatiques de 92 %.
Un autre exemple où Appinventiv a aidé YouCOMM à construire une solution révolutionnaire pour transformer la communication avec les patients hospitalisés en fournissant un accès en temps réel à l'aide médicale. Grâce à un système de messagerie patient personnalisable, les patients peuvent facilement informer le personnel de leurs besoins par le biais de commandes vocales et de gestes de la tête.
Grâce à notre expertise et à notre équipe axée sur le client, nous fournissons les services d'étiquetage de données qui vous aideront à surmonter les défis en vous fournissant des services d'étiquetage de données holistiques en fonction de vos besoins et exigences spécifiques.
En tirant parti de la vaste gamme d'outils requis pour le marquage et l'annotation des données, Appinventiv peut améliorer vos processus de formation de données pour simplifier les modèles complexes. Cela nous permet de surperformer en termes de précision de segmentation, de classification, et par la suite d'étiquetage des données qui sera simple et rapide.
Emballer!
"Le pouvoir de l'intelligence artificielle est tellement incroyable qu'il va changer la société de manière très profonde." - Bill Gates
L'intelligence artificielle a le potentiel de faciliter la vie humaine, faisant ainsi du bien à la société. Sa capacité à trier d'énormes quantités de données en instructions significatives à l'aide de l'étiquetage des données a aidé les industries à progresser et à se développer à pas de géant.
FAQ
Q. Quelles sont les meilleures pratiques pour perfectionner l'étiquetage des données ?
R. En fonction de l'approche que vous adoptez pour l'étiquetage des données, vous pouvez suivre certaines bonnes pratiques :
- Assurez-vous que les données recueillies sont adéquates, correctement nettoyées et traitées.
- En fonction du secteur, attribuez la tâche uniquement aux étiqueteurs de données experts du domaine.
- Assurez-vous qu'une approche uniforme est suivie par l'équipe en leur fournissant les critères des techniques d'annotation à suivre.
- Suivez un processus de maker-checker en affectant plusieurs annotateurs pour l'étiquetage croisé.
Q. Quels sont les avantages de l'étiquetage des données ?
A. L'étiquetage des données aide à fournir une meilleure clarté sur le contexte, la qualité et la convivialité pour faire une prédiction précise des données. Ceci, à son tour, contribue à améliorer la convivialité des données des variables du modèle.
Q. Quels sont les différents éléments à prendre en compte lors de la présélection des entreprises d'étiquetage des données ?
R. Il y a cinq paramètres à prendre en compte lors du choix des services d'étiquettes de données pour l'apprentissage automatique.
- Évolutivité du processus d'étiquetage des données
- Coût du service d'étiquetage des données
- Sécurité des données
- Plateforme d'étiquetage des données